Two Sub-Quadratic Sorts
October 30, 2009
In the previous exercise we looked at three sorting algorithms that work in quadratic time. Today we look at two sorting algorithms, each a minor variant on one of the previous algorithms, that work much more quickly.
Comb sort is a variant of bubble sort popularized by Stephen Lacey and Richard Box in an article in the April 1991 edition of Byte Magazine. The basic idea is to quickly eliminate turtles, small values near the end of the array, since they greatly hamper the speed of the sort. In bubble sort, the elements being compared are always adjacent; the gap between them is 1. In comb sort, the gap is initially the length of the list being sorted; the array is sorted using that gap size, then the gap is reduced and the array is sorted again, and so on until the gap is reduced to 1, when the sort reduces to ordinary bubble sort. Since early stages with large gaps quickly move turtles near the front of the array, later stages with smaller gaps have less work to do, and the sorting algorithm becomes relatively efficient. Most often, the gap is reduced by a factor of 1.3 at each step, though other shrink factors are sometimes used.
In the same way that comb sort is a variant of bubble sort, shell sort, invented by Donald Shell in 1959, is a variant of insertion sort that attempts to eliminate large disorder in early stages so that later stages have less work to do. Shell sort performs multiple stages of insertion sort, using a diminishing sequence of gaps that eventually reaches 1; a popular gap sequence is …, 364, 121, 40, 13, 4, 1.
Your task is to write functions that perform comb sort and shell sort, in the same manner as the previous exercise. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Three Quadratic Sorts
October 27, 2009
Sorting is one of the most common computing tasks. In the days of large mainframes, sorting would often account for ten percent of a computer’s workload, and there were complicated procedures involving large free-standing tape machines for sorting more records than could fit in the computer’s memory; the programmer who could shave a few percentage points of time or core memory space off the standard system sort was a hero. Nowadays, most programmers simply call their local sort library, and never worry about how it works.
We are going to explore classical sorting algorithms in the next several exercises. The rules of the game: We will be sorting arrays of integers with elements stored in locations zero through n−1, where n is the number of elements in the array. We will always sort into ascending order, and will use <, never ≤, to compare array elements. All sorting functions will be called with two parameters, the name of the array and its length.
Today, we will look at three simple sorting algorithms. Bubble sort works by repeatedly stepping through the array to be sorted, comparing each pair of adjacent elements and interchanging them if they are in the wrong order, until the array is sorted. Selection sort works by repeatedly passing through the array, at each pass finding the minimum element of the array, interchanging it with the first element of the array, then repeating on the sub-array that excludes the first element of the array. Insertion sort works the same way that card players generally sort their hands; starting from an empty hand, they pick up a card, insert it into the correct position, then repeat with each new card until no cards remain.
Your task is to write functions that sort an array using bubble sort, selection sort, and insertion sort; you should also write a test program that can be used for any of the sorting algorithms. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Mr. S. and Mr. P.
October 23, 2009
John McCarthy, who discovered Lisp, attributes this puzzle to Hans Freudenthal:
We pick two numbers a and b, so that 99 ≥ a ≥ b ≥ 2. We tell Mr. P. the product a × b and Mr. S. the sum a + b. Then Mr. S. and Mr. P. engage in the following dialog:
Mr. P.: I don’t know the numbers.
Mr. S.: I knew you didn’t know. I don’t know either.
Mr. P.: Now I know the numbers.
Mr. S.: Now I know them too.
Find the numbers a and b.
Your task is to find the two numbers. When you are finished, you are welcome to read or run a suggested solution, or to post your solution or discuss the exercise in the comments below.
Shuffle
October 20, 2009
It is easy to shuffle an array by stepping through the array, swapping each element with a forward element (an element at an index greater than or equal to the current element) until the next-to-last element is reached. It is harder to shuffle a linked list, because lists don’t permit ready access to any element other than the first.
Your task is to write functions that shuffle an array and a linked list. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Growable Arrays
October 16, 2009
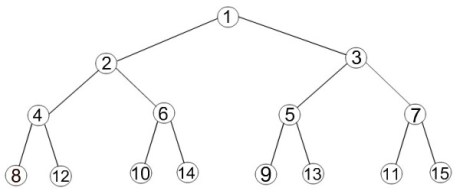 Most programming languages provide a data structure called an array that provides constant-time access and update to its elements, at the cost of fixing the size of the array in advance of its use; Scheme calls that data structure a vector. In their book The Practice of Programming, Brian Kernighan and Rob Pike describe arrays that can grow during use, using the C language and its
Most programming languages provide a data structure called an array that provides constant-time access and update to its elements, at the cost of fixing the size of the array in advance of its use; Scheme calls that data structure a vector. In their book The Practice of Programming, Brian Kernighan and Rob Pike describe arrays that can grow during use, using the C language and its realloc function to double the size of an array when needed. In this exercise we will create a tree-based data structure that provides logarithmic-time access and update to its elements without requiring periodic reallocations, based on the functional arrays in Lawrence Paulson’s book ML for the Working Programmer.
A growable array has subscripts from 1 to n, where n is the current number of elements in the array. The elements are stored in a binary tree. To find the k‘th element of the array, start at the root and repeatedly divide k by two until it becomes one, moving left if the remainder is zero and right if the remainder is one. For instance, the 12th element of the array is found by moving left, left and right from the root, as shown in the diagram at right. The operations on a growable array are get, which retrieves an element of the array, put, which returns a new array containing the element, and hirem, which shrinks the array by a single element. The put operation can increase the upper bound of the array by one.
Your task is to implement the growable array data structure. When you are finished, you are welcome to read or run a suggested solution, or to post your solution or discuss the exercise in the comments below.
Bifid Cipher
October 13, 2009
The bifid cipher was invented by the French cryptographer Felix Delastelle in 1901. Though never used militarily, it is popular among classical cryptographers because it is simple to operate manually yet reasonably secure. Bifid uses a Polybius square to substitute a digit-pair for each plain-text letter, then transposition causes fractionation of the digit pairs, creating diffusion, and finally the transposed digits are reformed into cipher-text letters. An example is shown below:
1 2 3 4 5
1 A B C D E
2 F G H I K
3 L M N O P
4 Q R S T U
5 V W X Y Z
Our “key” is just the letters of the alphabet, in order, with J omitted; other methods of building a Polybius square have been discussed in previous exercises. To encipher a message, write the row and column numbers of the letters in two rows below the message:
P R O G R A M M I N G P R A X I S
3 4 3 2 4 1 3 3 2 3 2 3 4 1 5 2 4
5 2 4 2 2 1 2 2 4 3 2 5 2 1 3 4 3
Then the digits are read off by rows, in pairs, and converted back to letters:
34 32 41 33 23 23 41 52 45 24 22 12 24 32 52 13 43
O M Q N H H Q W U I G B I M W C S
So the cipher-text is OMQNHHQWUIGBIMWCS. Deciphering is the inverse operation.
Some variants of bifid break the plain-text into blocks of a given length, called the period, before encipherment, then encipher each block separately; a common period is five. A 6 × 6 variant that includes digits is also common. Another variant of bifid, called trifid, uses a 3 × 3 × 3 cube instead of a square, on the theory that if fractionating by two is good, fractionating by three is better.
Your task is to write functions that encipher and decipher messages using the bifid cipher. When you are finished, you are welcome to read or run a suggested solution, or to post your solution or discuss the exercise in the comments below.
Calculating Pi
October 9, 2009
 Pi, or π, is a mathematical constant with a value that is the ratio of a circle’s circumference to its diameter. It has been known since antiquity that the ratio of the circumference of a circle to its diameter is the same for all circles; the ancient Egyptians, Indians, and Babylonians had all calculated approximations for π about two millenia before the birth of Christ. π, which is approximately equal to 3.14159, is one of the most important constants in math, science and engineering; it pops up regularly in studies of geometry, trigonometry and calculus, Einstein used π in his field equation of general relativity, and it appears in many statistical distributions. In a previous exercise we used a spigot algorithm to calculate the digits of π; our exercise today will use two different methods to calculate the value of π.
Pi, or π, is a mathematical constant with a value that is the ratio of a circle’s circumference to its diameter. It has been known since antiquity that the ratio of the circumference of a circle to its diameter is the same for all circles; the ancient Egyptians, Indians, and Babylonians had all calculated approximations for π about two millenia before the birth of Christ. π, which is approximately equal to 3.14159, is one of the most important constants in math, science and engineering; it pops up regularly in studies of geometry, trigonometry and calculus, Einstein used π in his field equation of general relativity, and it appears in many statistical distributions. In a previous exercise we used a spigot algorithm to calculate the digits of π; our exercise today will use two different methods to calculate the value of π.
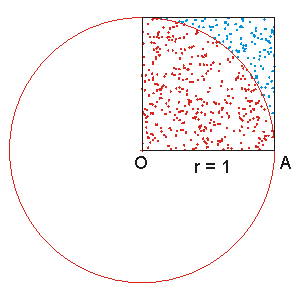
An interesting method for calculating π uses Monte Carlo simulation. If a circle of radius r is inscribed in a square with sides of length 2r, the area of the circle will be πr2 and the area of the square will be (2r)2, so the ratio of the area of the circle to the area of the square will be π/4. Another way of looking at this, as on the diagram, is to consider just the first quadrant of the circle; the square has an area of r 2, and the portion of the circle within the square has an area of πr2/4.
By taking a large number of points randomly distributed throughout the square and counting how many are within the inscribed circle, we can estimate the value of π. We could do that by building a model, scattering sand over it, and counting the individual grains of sand, but since we are programmers, it is easier to write a program to do the counting for us.
Your first task is to implement a program to calculate the value of π using the Monte Carlo method described above.
The second method is due to Archimedes (287–212 BC), a Greek mathematician who lived in Syracuse, who famously bounded the value of π within a small range by measuring the perimeters of inscribed and circumscribed regular polygons with ninety-six sides: 223/71 < π < 22/7.
 Consider a circle with radius 1 and circumference 2π in which regular polygons of 3 × 2n-1 sides are inscribed and circumscribed; the diagram for n = 2 is shown at right. If bn is the semiperimeter of the inscribed polygon, and an is the semiperimeter of the circumscribed polygon, then as n increases, b1, b2, b3, … defines an increasing sequence, and a1, a2, a3, … defines a decreasing sequence, each with limit π.
Consider a circle with radius 1 and circumference 2π in which regular polygons of 3 × 2n-1 sides are inscribed and circumscribed; the diagram for n = 2 is shown at right. If bn is the semiperimeter of the inscribed polygon, and an is the semiperimeter of the circumscribed polygon, then as n increases, b1, b2, b3, … defines an increasing sequence, and a1, a2, a3, … defines a decreasing sequence, each with limit π.
Given K = 3 × 2n-1, the semiperimeters are an = K tan(π/K) and bn = K sin(π/K) by the definitions of sine and tangent. Likewise, an+1 = 2K tan(π/2K) and a n+1 = 2K sin(π/2K).
Then, simple trigonometry allows us to calculate (1/an + 1/bn) = 2/an+1 and an+1bn = (bn+1)2. Archimedes started with a1 = 3 tan(π/3) = 3√3 and b1 = 3 sin(π/3) = 3√3/2 and calculated b6 < π < a6.
Archimedes, of course, didn’t have trigonometry available to him, as it hadn’t been invented yet; he had to work out the geometry directly, as well as making all the calculations by hand!
Your second task is to write a function that calculates the bounds of π using Archimedes’ algorithm. You can test your function for n = 6, as Archimedes did. When you are finished, you are welcome to read or run a suggested solution, or to post your solution or discuss the exercise in the comments below.
MapReduce
October 6, 2009
MapReduce is a programming idiom that provides a convenient expression for programs that combine like items into equivalence classes. The idiom was developed by Google as a way to exploit large clusters of computers operating in parallel on large bodies of data, but is also useful as a way of structuring certain types of programs. Jeffrey Dean and Sanjay Ghemawat, in their paper MapReduce: Simplified Data Processing on Large Clusters, describe the idiom:
Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.
Google uses MapReduce to automatically parallelize computations across the large sets of machines at their data centers, gracefully “partitioning the input data, scheduling the program’s execution across a set of machines, handling machine failures, and managing the required inter-machine communication.” Our aspirations (and our budget) are more modest: build a framework for exploiting the mapreduce idiom in out day-to-day programs. Consider the following examples:
- Count the frequencies of letters in a string or words in a text. The mapper associates the value 1 with each character or word as the key, and the reducer is simply the addition operator, adding all the 1s to count the words.
- Produce a cross-reference listing of a program source text. The mapper associates each identifier with the line number where it appears, and the reducer collects the line numbers for each identifier, discarding duplicates.
- Identify anagrams in a word list. The mapper “signs” each word by sorting its characters into alphabetical order, and the reducer brings together words with common signatures.
The map-reduce function takes four parameters: the mapping function, the reducing function, a less-than predicate that operates on keys, and the input list. The mapping function takes an item from the input list and returns a key/value pair, and the reducing function takes a key, a new value and an existing value and merges the new value into the existing value. A useful variant of the map-reduce function reads input from a file instead of a list; it replaces the input list parameter with a filename and adds a fifth parameter, a reading function that fetches the next input item from the file.
Your task is to write the map-reduce and map-reduce-input functions. When you are finished, you are welcome to read or run a suggested solution, or to post your solution or discuss the exercise in the comments below.
Red-Black Trees
October 2, 2009

A red-black tree is a data structure, similar to a binary tree, which is always approximately balanced, so that individual insert and lookup operations take only O(log n) time. Red-black trees are popular because of their good performance and the relative simplicity of their balancing operations. Our discussion of red-black trees is drawn from Section 3.3 of Chris Okasaki’s book Purely Functional Data Structures.
A red-black tree is a binary search tree in which each node is colored either red or black. A red-black tree maintains two invariants that ensure its balance:
- No red node ever has a red child.
- Every path from the root to an empty node has the same number of black nodes.
Thus, the shortest possible path has only black nodes, and the longest possible path has alternating red and black nodes, so the longest path is never more than twice as long as the shortest path, and the tree is approximately balanced.
Lookup in red-black trees is identical to its binary-tree counterpart; the colors make no difference. The balance condition is maintained by the insert operation. Each new node is initially colored red. If its parent is black, the tree remains balanced, and nothing need be done. However, if its parent is red, the first invariant is violated, and a balancing function is called to repair the violation by rewriting the black-red-red path as a red node with two black children. This may propagate the invariant up the tree, so the balancing function is called recursively until it reaches the root of the tree, which is always recolored black.
Your task is to write functions to maintain red-black trees; you should provide an insert function, a lookup function, and an enlist function that returns a list with the nodes of the tree in order. Each node should contain a key and a value, so the red-black tree can be used as a dictionary, in the manner of the treaps and ternary search tries that we have written in previous exercises. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
