Rule 30 RNG
April 29, 2011
 We have examined several different random number generators in past exercises, including Donald Knuth’s lagged-fibonacci generator that is used in the Standard Prelude. We also looked at cellular automata in a previous exercise. In today’s exercise we combine random number generators and cellular automata by looking at a random number generator developed by Stephen Wolfram, based on the Rule 30 cellular automaton of his book A New Kind of Science. Our random number generator will be similar to that in Mathematica; it is not cryptographically secure, but is suitable for simulation, as long as you avoid the occasional bad seed, like 0.
We have examined several different random number generators in past exercises, including Donald Knuth’s lagged-fibonacci generator that is used in the Standard Prelude. We also looked at cellular automata in a previous exercise. In today’s exercise we combine random number generators and cellular automata by looking at a random number generator developed by Stephen Wolfram, based on the Rule 30 cellular automaton of his book A New Kind of Science. Our random number generator will be similar to that in Mathematica; it is not cryptographically secure, but is suitable for simulation, as long as you avoid the occasional bad seed, like 0.
The cellular automata we are discussing have a state consisting of a row of cells; each cell can be in either of two states, 0 or 1. Unlike the cellular automata of the previous exercise, the row contains a finite number of cells and is considered to “wrap around” at the ends. A new state is generated based on the current state by assigning to each cell in the new state a value determined by the same-indexed cell in the previous state as well as the two cells immediately adjacent to it. The chart below shows the rule that determines the cell value in the new state:
| ■ ■ ■ | ■ ■ □ | ■ □ ■ | ■ □ □ | □ ■ ■ | □ ■ □ | □ □ ■ | □ □ □ |
| □ | □ | □ | ■ | ■ | ■ | ■ | □ |
The name Rule 30 comes from the binary-to-decimal conversion of the new values in each of the cells. Taking the same-indexed cell in each successive state gives a sequence of random bits; collect enough of them and you can convert them to a number.
In Wolfram’s book, the various cellular automata are studied based on an infinite row that starts with a single 1-cell, with all remaining cells having a value of 0; the successive states of that cellular automaton are shown in the image above-right. In a random-number generator, the initial state is seeded with 1s and 0s in some user-defined pattern.
Your task is to write a random-number generator based on the Rule 30 cellular automaton. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Miscellanea
April 26, 2011
We have three short exercises today.
FizzBuzz: Looking back over past exercises, I was surprised to find that we haven’t done this classic interview question. You are to write a function that displays the numbers from 1 to an input parameter n, one per line, except that if the current number is divisible by 3 the function should write “Fizz” instead of the number, if the current number is divisible by 5 the function should write “Buzz” instead of the number, and if the current number is divisible by both 3 and 5 the function should write “FizzBuzz” instead of the number. For instance, if n is 20, the program should write 1, 2, Fizz, 4, Buzz, Fizz, 7, 8, Fizz, Buzz, 11, Fizz, 13, 14, FizzBuzz, 16, 17, Fizz, 19, and Buzz on twenty successive lines.
Prime Words: Consider that a word consisting of digits and the letters A through Z can represent an integer in base 36, where the digits represent their base-10 counterparts, A is a decimal 10, B is a decimal 11, and so on, until Z is a decimal 35. For instance, PRAXIS36 = P36 × 365 + R36 × 364 + A36 × 363 + X36 × 362 + I36 × 361 + S36 × 360 = 25 × 365 + 27 × 364 + 10 × 363 + 33 × 362 + 18 × 361 + 28 × 360 = 25 × 60466176 + 27 × 1679616 + 10 × 46656 + 33 × 1296 + 18 × 36 + 28 × 1 = 1557514036. You are to write a function that takes a base-36 number as input and returns true if the number is prime and false if the number is composite.
Split A List: You are to write a function that takes an input list and returns two lists, the first half of the input list and the second half of the input list. If the input list has an odd number of elements, it is your choice in which half to place the center element. You are only permitted to scan the list once.
Your task is to write the three functions described above. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Xref
April 22, 2011
In the old days, when programs were written on punch cards or paper tape and editors didn’t provide regular-expression searches, most compilers provided a cross-reference utility that showed each use of each identifier in the program. You don’t often see cross-referencers any more, and that’s too bad, because a cross-referencer can provide good clues about the structure of a program; looking at a cross-reference listing can be a good way to start examining an unfamiliar program. Here’s some sample output from a Scheme cross-referencer, with the identifier as the first word on each line followed by a list of line numbers where the identifier appears:
0 28
1 18
< 27
= 30
?!.+-*/<=>:$%^&_~@ 5
a 24 25 26 27
add1 20
and 26 30
b 24 25 26 27
c 3 4 5 8 9 10 13
caar 30 32 36 37
car 25 26
cdar 30 33 34 36 37
cdr 27 31 34 37
char-alphabetic? 4
char-in-ident? 3 10
char-numeric? 4
char=? 13
cond 9 19 29
cons 11 21
cs 8 9 11 12 14
define 3 7 16 23 24
display 33 36
else 14 21 35
eof-object? 9 19
file 16 17
get-ident 7 18 20 21
identifiers 3
if 9
lambda 17
let 8 11 18 28
line 18 20 21
list->string 9 12
loop 8 11 14 18 20 21 28 31 34 37
lt? 24 28
member 5
newline 13 29 35
not 35
null? 9 29
or 4 25
pair? 12
peek-char 8 11 14
prev-line 28 30 31
prev-word 28 30 31 32 34 35
read-char 11 13 14
reverse 9 12
scheme 3
sort 28
string->list 5
string<? 25
string=? 20 26 30 32 35
w 18 19 20 21
when 35
with-input-from-file 17
ws 18 19 20 21 23 28 29 30 31 32 33 34 36 37
x 11
xref 1 16
xref-out 19 23
A quick look suggests that this program reads a text file (with-input-from-file, read-char, eof-object?) and does some kind of processing on its characters (char-alphabetic?, char-numeric?). There is some list-handling (car, cdr, string->list), loop is used conventionally, and ws seems to be some kind of key to understanding what the program does. And there is an unholy mess on line 5.
Your task is to write a cross-referencer for your chosen language. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Same Five Digits
April 19, 2011
[Today’s exercise was written by guest author Bob Miller. Bob has been writing system software for Unix since the VAX was new and shiny, and his current hobby is writing Scheme interpreters. Suggestions for exercises are always welcome, or you may wish to contribute your own exercise; feel free to contact me if you are interested.]
Enigma is a weekly column in New Scientist. Every week it has a new puzzle. Some of the Enigma puzzles could be solved using a computer.
A recent puzzle, Enigma Number 1638, is in that category:
I have written down three different 5-digit perfect squares, which between them use five different digits. Each of the five digits is used a different number of times, the five numbers of times being the same as the five digits of the perfect squares. No digit is used its own number of times. If you knew which digit I have used just once you could deduce my three squares with certainty.
What are my three perfect squares?
Your task is to write a program that finds and prints the three perfect squares. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Partition Numbers
April 15, 2011
The partition-number function P(n) gives the number of ways of writing n as the sum of positive integers, irrespective of the order of the addends. For instance P(4) = 5, since 4 = 4 = 3 + 1 = 2 + 2 = 2 + 1 + 1 = 1 + 1 + 1 + 1. Sloane’s A000041 gives the first ten partition numbers as 1, 2, 3, 5, 7, 11, 15, 22, 30, and 42; the numerous references to that sequence point to many fascinating facts about partition numbers, including their close association with pentagonal numbers. By convention, P(0) = 1 and P(n) = 0 for negative n. Partition numbers are normally calculated by the formula, which was discovered by Leonhard Euler:
![P(n) = \sum_{k=1}^n (-1)^{k+1} \left[ P\left( n - \frac{k\left(3k-1\right)}{2} \right) + P\left( n - \frac{k\left(3k+1\right)}{2} \right) \right]](https://s0.wp.com/latex.php?latex=P%28n%29+%3D+%5Csum_%7Bk%3D1%7D%5En+%28-1%29%5E%7Bk%2B1%7D+%5Cleft%5B+P%5Cleft%28+n+-+%5Cfrac%7Bk%5Cleft%283k-1%5Cright%29%7D%7B2%7D+%5Cright%29+%2B+P%5Cleft%28+n+-+%5Cfrac%7Bk%5Cleft%283k%2B1%5Cright%29%7D%7B2%7D+%5Cright%29+%5Cright%5D&bg=ffffff&fg=555555&s=0&c=20201002)
Your task is to write a function that computes P(n), and to calculate P(1000). When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
House Of Representatives
April 12, 2011
The United States counts its citizens every ten years, and the result of that census is used to allocate the 435 congressional seats in the House of Representatives to the 50 States. Since 1940, that allocation has been done using a method devised by Edward Huntington and Joseph Hill that minimizes percentage differences in the sizes of the congressional districts.
The Huntington-Hill method begins by assigning one representative to each State. Then each of the remaining representatives is assigned to a State in a succession of rounds by computing 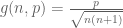
For instance, once each State has been assigned one representative, the geometric mean g(n, p) for each State is its population divided by the square root of 2. Since California has the biggest population, it gets the 51st representative. Then its geometric mean is recalculated as its population divided by the square root of 2 × 3 = 6, and in the second round the 52nd representative is assigned to Texas, which has the second-highest population, since it now has the largest geometric mean g(n, p). This continues for 435 − 50 = 385 rounds until all the representatives have been assigned.
Your task is to compute the apportionment of seats in the House of Representatives; the population data is given on the next page. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Credit Card Validation
April 8, 2011
Most credit card numbers, and many other identification numbers including the Canadian Social Insurance Number, can be validated by an algorithm developed by Hans Peter Luhn of IBM, described in U. S. Patent 2950048 in 1954 (software patents are nothing new!), and now in the public domain. The Luhn algorithm will detect almost any single-digit error, almost all transpositions of adjacent digits except 09 and 90, and many other errors.
The Luhn algorithm works from right-to-left, with the right-most digit being the check digit. Alternate digits, starting with the first digit to left of the check digit, are doubled. Then the digit-sums of all the numbers, both undoubled and doubled, are added. The number is valid if the sum is divisible by ten.
For example, the number 49927398716 is valid according to the Luhn algorithm. Starting from the right, the sum is 6 + (2) + 7 + (1 + 6) + 9 + (6) + 7 + (4) + 9 + (1 + 8) + 4 = 70, which is divisible by 10; the digit-sums of the doubled digits have been shown in parentheses.
Your task is to write two functions, one that adds a check digit to a identifying number and one that tests if an identifying number is valid. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Fortune
April 5, 2011
We have today another in our occasional series of re-implementations of Unix V7 commands. The fortune command prints a random aphorism on the user’s terminal; many people put the fortune command in their login script so they get a new aphorism every time they login. Here’s the man page:
NAME
fortune
SYNOPSIS
fortune [ file ]
DESCRIPTION
Fortune prints a one-line aphorism chosen at random. If a file is specified, the sayings are taken from that file; otherwise they are selected from /usr/games/lib/fortunes.
FILES
/usr/games/lib/fortunes - sayings
The fortunes are stored in a file, one fortune per line. The original Unix V7 fortunes file, available from http://minnie.tuhs.org/cgi-bin/utree.pl?file=V7/usr/games/lib/fortunes, is reproduced at the end of the exercise.
Your task is to implement the Unix V7 fortune program. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Maximum Difference In An Array
April 1, 2011
Today’s problem is this:
Given an array X, find the j and i that maximizes Xj − Xi, subject to the condition that i ≤ j. If two different i,j pairs have equal differences, choose the “leftmost shortest” pair with the smallest i and, in case of a tie, the smallest j.
For instance, given an array [4, 3, 9, 1, 8, 2, 6, 7, 5], the maximum difference is 7 when i=3 and j=4. Given the array [4, 2, 9, 1, 8, 3, 6, 7, 5], the maximum difference of 7 appears at two points, but by the leftmost-shortest rule the desired result is i=1 and j=2. I and j need not be adjacent, as in the array [4, 3, 9, 1, 2, 6, 7, 8, 5], where the maximum difference of 7 is achieved when i=3 and j=7. If the array is monotonically decreasing the maximum difference is 0, which by the leftmost-shortest rule occurs when i=0 and j=0.
There are at least two solutions. The obvious solution that runs in quadratic time uses two nested loops, the outer loop over i from 0 to the length of the array n and the inner loop over j from i+1 to n, computing the difference between Xi and Xj and saving the result whenever a new maximum difference is found. There is also a clever linear-time solution that traverses the array once, simultaneously searching for a new minimum value and a new maximum difference; you’ll get it if you think about it for a minute.
Your task is to write both the quadratic and linear functions to compute the maximum difference in an array, and also a test function that demonstrates they are correct. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
