World Cup Prognostication
June 29, 2010
 On Saturday morning, inspired by Andrew Moylan’s article on Wolfram’s Blog, I sat down to work out a simulation of the knockout stage of the World Cup competition. I used the bracket shown at right, and found elo ratings of the sixteen teams, as of that morning, at Wikipedia:
On Saturday morning, inspired by Andrew Moylan’s article on Wolfram’s Blog, I sat down to work out a simulation of the knockout stage of the World Cup competition. I used the bracket shown at right, and found elo ratings of the sixteen teams, as of that morning, at Wikipedia:
1 BRA Brazil 2082
2 ESP Spain 2061
3 NED Netherlands 2045
4 ARG Argentina 1966
5 ENG England 1945
6 GER Germany 1930
7 URU Uruguay 1890
8 CHI Chile 1883
9 POR Portugal 1874
10 MEX Mexico 1873
15 USA United States 1785
19 PAR Paraguay 1771
25 KOR Korea 1746
26 JPN Japan 1744
32 GHA Ghana 1711
45 SVK Slovakia 1654
The table shows that there are forty-four national teams with ratings higher than Slovakia’s rating of 1654; they are lucky to be in the tournament.
The likelihood that a team will win its match can be computed from the elo rankings of the team and its opponent according to the formula 
Every time a match is played, the elo rating of a team changes. The amount of the change is based on the actual result as compared to the expected result. If a team wins when they have a high expectation of winning, their elo rating goes up by a small amount, since they were expected to win. However, if a team wins when they have a low expectation of winning, their elo rating goes up by a large amount. The formula is 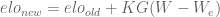
Your task is to use the data and formulas described above to simulate the knockout stage of the World Cup a million times and report the number of times each nation wins. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Learn A New Language
June 25, 2010
There are hundreds, probably thousands, of programming language. Some are general-purpose, others are intended for a limited domain. Some are useful, most get in your way. Some are just weird. We programmers frequently have to learn a new language, or re-learn an old one, or adapt to improvements from the vendor.
A good way to learn a new language is to write in the new language a familiar program from an old language with which you are experienced. Many people have written that they use the exercises at Programming Praxis as a way to get started with a new language.
Your task is to write a program that solves the Programming Praxis exercise of your choice in a programming language in which you are not proficient. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Matrix Operations
June 22, 2010
Our Standard Prelude provides a matrix datatype with create, lookup and setting operations. In today’s exercise we extend the matrix datatype with some mathematical operations: sum two matrices, multiply a matrix by a scalar, multiply two matrices, and transpose a matrix.
- Addition of two matrices is done by adding elements in corresponding positions, assuming identical dimensions. For example:
- Multiplying a scalar times a matrix is done by multiplying the scalar times each element in turn. For example:
- The product of an m×n matrix A and an n×p matrix B is the m×p matrix C whose entries are defined by
. For example:
- The transpose of a matrix interchanges the rows and columns of a matrix. For example:

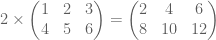
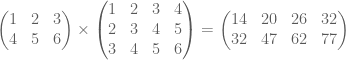
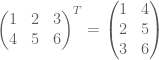
Your task is to write functions that perform the four matrix operations described above. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Parsing Command-Line Arguments
June 18, 2010
Some unix systems provide a system call getopt that provides a convenient interface for programs that parse their command-line arguments in a conventional manner. getopt usually takes three arguments: a string that describes the allowable arguments, an error message to be provided to the user in the event of an invalid argument, and the list of command-line arguments (or a vector and count). The option string gives all possible options; any that take an argument are followed by a colon. For instance, for the Unix V7 diff command, the option string is "befhnmD:". The parser recognizes options with a leading dash, stops at the first argument that doesn’t start with a dash or with the "--" argument, and allows options without required arguments to be combined in a single option string; for instance, the command diff -eh -D string file1 file2 finds three options, e, h and D, including the string argument to the D option. The getopt function returns a list of option/argument pairs, with null argument for options that don’t take an argument, and a list of the remaining non-option arguements.
Your task is to write the getopt function. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Natural Join
June 15, 2010
In relational databases, the natural join of two tables is an operator that takes two tables as input and returns a new table that combines the two input tables on their common keys. If the input tables are sorted, the join simply scans the two tables, writing records for the cross-product of all records with equal keys. For instance, the join of the two tables
Key Field1 Field2 Key Field3
A w p A 1
B x q and A 2
B y r B 3
C z s
is the table
Key Field1 Field2 Field3
A w p 1
A w p 2
B x q 3
B y r 3
We represent a table as a file; each line is a record, and fields are separated by tabs. For simplicity, we’ll assume that the first field in each record is the key.
Your task is to write a program that takes two input files representing tables (you may assume they are sorted) and produces their natural join as output. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
N-Queens
June 11, 2010
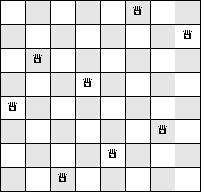 We present today a classic exercise that has been on my to-do list since the start of Programming Praxis.
We present today a classic exercise that has been on my to-do list since the start of Programming Praxis.
The n-queens problem is to find all possible ways to place n queens on an n × n chess board in such a way that no two queens share a row, column, or diagonal. The diagram at right shows one way that can be done on a standard 8 × 8 chess board.
Your task is to write a program to find all such placements. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Diff
June 8, 2010
The unix program diff identifies differences between text files; it is most useful for comparing two versions of a program.
Given the longest common subsequence between two files, which we computed in a previous exercise, it is easy to compute the diff between the two files; the diff is just those lines that aren’t part of the lcs.
Your task is to write a program that finds the differences between two files. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Williams’ P+1 Factorization Algorithm
June 4, 2010
Hugh Williams invented the p+1 integer factorization method in 1982 based on John Pollard’s p-1 integer factorization method; the p+1 method finds a factor p when p is smooth with respect to a bound B. We noted in a previous exercise the similar structure of Pollard’s p-1 method and Lenstra’s elliptic curve method, and Williams’ p+1 method shares the same two-stage structure; Pollard’s p-1 method performs multiplications modulo p, Lenstra’s elliptic curve method performs multiplications over an elliptic curve, and Williams’ p+1 method performs multiplications over a quadratic field using Lucas sequences (similar to the Lucas chain in the Baillie-Wagstaff primality-testing exercise). A good description of Williams’ p+1 method is given at http://www.mersennewiki.org/index.php/P_Plus_1_Factorization_Method.
Williams’ p+1 method uses the Lucas sequence V0 = 2, V1 = A, Vj = A · Vj−1 − Vj−2, with all operations modulo N, where A is an integer greater than 2. Multiplication by successive prime powers is done as in Pollard’s p-1 algorithm; when all the products to the bound B are accumulated, the greatest common divisor of N and the result VB − 2 may be a divisor of N if all the factors of p+1 are less than B. However, if A2 − 4 is a quadratic non-residue of p, the calculation will fail, so several attempts must be made with different values of A before concluding that p+1 is not B-smooth.
Given the addition formula Vm+n = Vm Vn − Vm−n and the doubling formula V2m = Vm × Vm − 2, multiplication is done by means of a Lucas sequence that computes two values at a time. Starting with the pair Vkn and V(k+1)n, and looking at the bits in the binary representation of the multiplier M, excluding the most significant bit (which is always 1) and working from most significant to least significant, calculate the pair V2kn, V(2k+1)n when the bit is zero and the pair V(2k+1)n, V2(k+1)n when the bit is one.
The second stage finds factors that are B1-smooth except for a single prime factor in the range B1 to B2. It can be done in a similar manner to the second stage of Pollard’s p-1 method, but a little bit of algebra gives us a better second stage. Assuming that Vn is the point that survives the first stage, multiply the products Vk − Vn for each k divisible by 6 between B1 and B2, then take the greatest common divisor of the product with n to reveal the factor.
Your task is to write a program that factors integers using Williams’ p+1 algorithm. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Unwrapping A Spiral
June 1, 2010
This exercise appeared on Proggit a while ago. The task is to enumerate the elements of a matrix in spiral order. For instance, consider the matrix:
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
17 18 19 20
The spiral starts across the first row, yielding 1, 2, 3, and 4. Then the spiral turns right and runs down the right column, yielding 8, 12, 16, and 20. The spiral turns right again and runs across the bottom row, from right to left, yielding 19, 18, and 17. Then up the first column with 13, 9, 5, right with 6 and 7, down with 11 and 15, right to 14, and up to 10. Thus, unwrapping the given matrix in a spiral gives the list of elements 1, 2, 3, 4, 8, 12, 16, 20, 19, 18, 17, 13, 9, 5, 6, 7, 11, 15, 14, and 10.
Your task is to write a function to unwrap spirals. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
