House Of Representatives
April 12, 2011
The United States counts its citizens every ten years, and the result of that census is used to allocate the 435 congressional seats in the House of Representatives to the 50 States. Since 1940, that allocation has been done using a method devised by Edward Huntington and Joseph Hill that minimizes percentage differences in the sizes of the congressional districts.
The Huntington-Hill method begins by assigning one representative to each State. Then each of the remaining representatives is assigned to a State in a succession of rounds by computing 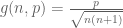
For instance, once each State has been assigned one representative, the geometric mean g(n, p) for each State is its population divided by the square root of 2. Since California has the biggest population, it gets the 51st representative. Then its geometric mean is recalculated as its population divided by the square root of 2 × 3 = 6, and in the second round the 52nd representative is assigned to Texas, which has the second-highest population, since it now has the largest geometric mean g(n, p). This continues for 435 − 50 = 385 rounds until all the representatives have been assigned.
Your task is to compute the apportionment of seats in the House of Representatives; the population data is given on the next page. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.

[…] today’s Programming Praxis exercise, our goal is to calculate the amount of seats each state gets in the […]
My Haskell solution (see http://bonsaicode.wordpress.com/2011/04/12/programming-praxis-house-of-representatives/ for a version with comments):
import Control.Arrow import qualified Data.List.Key as K import qualified Data.Map as M popData :: M.Map String Integer popData = M.fromList [("Alabama",4779736), ("Alaska",710231), ("Arizona",6392017), ("Arkansas",2915918), ("California",37253956), ("Colorado",5029196), ("Connecticut",3574097), ("Delaware",897934), ("Florida",18801310), ("Georgia",9687653), ("Hawaii",1360301), ("Idaho",1567582), ("Illinois",12830632), ("Indiana",6483802), ("Iowa",3046355), ("Kansas",2853118), ("Kentucky",4339367), ("Louisiana",4533372), ("Maine",1328361), ("Maryland",5773552), ("Massachusetts",6547629), ("Michigan",9883640), ("Minnesota",5303925), ("Mississippi",2967297), ("Missouri",5988927), ("Montana",989415), ("Nebraska",1826341), ("Nevada",2700551), ("New Hampshire",1316470), ("New Jersey",8791894), ("New Mexico",2059179), ("New York",19378102), ("North Carolina",9535483), ("North Dakota",672591), ("Ohio",11536504), ("Oklahoma",3751351), ("Oregon",3831074), ("Pennsylvania",12702379), ("Rhode Island",1052567), ("South Carolina",4625364), ("South Dakota",814180), ("Tennessee",6346105), ("Texas",25145561), ("Utah",2763885), ("Vermont",625741), ("Virginia",8001024), ("Washington",6724540), ("West Virginia",1852994), ("Wisconsin",5686986), ("Wyoming",563626)] house :: Int -> M.Map String Integer house seats = M.map fst $ iterate add (M.map ((,) 1) popData) !! k where add m = M.adjust (first succ) (maxMean m) m maxMean = fst . K.maximum (uncurry g . snd) . M.toList g n p = f p / sqrt (f n * (f n + 1)) where f = fromIntegral k = seats - M.size popData + 1 main :: IO () main = print . K.sort (negate . snd) . M.toList $ house 435A Python solution:
population_data = ( ("Alabama", 4779736), ("Alaska", 710231), ("Arizona", 6392017), ("Arkansas", 2915918), ("California", 37253956), ("Colorado", 5029196), ("Connecticut", 3574097), ("Delaware", 897934), ("Florida", 18801310), ("Georgia", 9687653), ("Hawaii", 1360301), ("Idaho", 1567582), ("Illinois", 12830632), ("Indiana", 6483802), ("Iowa", 3046355), ("Kansas", 2853118), ("Kentucky", 4339367), ("Louisiana", 4533372), ("Maine", 1328361), ("Maryland", 5773552), ("Massachusetts", 6547629), ("Michigan", 9883640), ("Minnesota", 5303925), ("Mississippi", 2967297), ("Missouri", 5988927), ("Montana", 989415), ("Nebraska", 1826341), ("Nevada", 2700551), ("New Hampshire", 1316470), ("New Jersey", 8791894), ("New Mexico", 2059179), ("New York", 19378102), ("North Carolina", 9535483), ("North Dakota", 672591), ("Ohio", 11536504), ("Oklahoma", 3751351), ("Oregon", 3831074), ("Pennsylvania", 12702379), ("Rhode Island", 1052567), ("South Carolina", 4625364), ("South Dakota", 814180), ("Tennessee", 6346105), ("Texas", 25145561), ("Utah", 2763885), ("Vermont", 625741), ("Virginia", 8001024), ("Washington", 6724540), ("West Virginia", 1852994), ("Wisconsin", 5686986), ("Wyoming", 563626) ) import math class State(object): def __init__(self,name,population): self.name = name self.population = population self.reps = 0 self.add_rep() def add_rep(self): self.reps += 1 self.gmean = self.population / math.sqrt(self.reps * (self.reps + 1)) def __str__(self): return "%s (%d)" % (self.name,self.reps) states = [State(name,population) for name,population in population_data] remaining = 435 - len(states) while remaining > 0: max(states,key=lambda x: x.gmean).add_rep() remaining -= 1 print "\n".join(str(state) for state in states)My solution and first attempt to play with upcoming C++0x standard (compiles nicely with GCC version 4.5): github
Thought I should admit that before posting I have read the solution and understood that using sorted vector and insertion via lower_bound function is not as nice as using priority queue :)
For this one I reformatted the source file as:
Alabama: 4779736
Alaska: 710231
Arizona: 6392017
…
use strict; my $DEBUG = 0; sub load(); sub calculate(); sub display(); sub update_ppr($); my %states; load(); calculate(); display(); sub load() { open(STATES, "states.txt") or die("Could not open states.txt: $!"); my @lines = <STATES>; close(STATES); for my $line (@lines) { die "invalid line: $line" unless $line =~ /^(.+?):\s*(\d+)$/; $states{$1}{population} = $2; } } sub calculate() { my $total = 0; # assign one representative to each state # and calculate people-per-representative for my $state (keys %states) { $states{$state}{reps} = 1; $total++; update_ppr($states{$state}); } # add a rep to the "most deserving" state until we have all 435 reps until (435 == $total) { my $highest_ppr = 0; my $state_with_highest_ppr = ""; # find the most deserving state for my $state (keys %states) { if ($states{$state}{ppr} > $highest_ppr) { $highest_ppr = $states{$state}{ppr}; $state_with_highest_ppr = $state; } elsif ($states{$state}{ppr} == $highest_ppr) { die("Two states with exactly the same ppr"); } } $DEBUG and print "$state_with_highest_ppr has a ppr of $highest_ppr; adding representative #", $states{$state_with_highest_ppr}{reps} + 1, "\n"; $states{$state_with_highest_ppr}{reps}++; $total++; update_ppr($states{$state_with_highest_ppr}); } } sub update_ppr($) { my $state = shift; # ppr = population / sqrt(reps * (reps + 1)) $state->{ppr} = $state->{population} / sqrt( $state->{reps} * ($state->{reps} + 1) ); } sub display() { my $reps = 0; for my $state (sort keys %states) { $reps += $states{$state}{reps}; print $state, "\t", $states{$state}{reps}, "\n"; } print "---\n"; print "Total\t", $reps, "\n"; }My Python solution.
My original solution involved a
State class, but pylint objected that it didn't have enough public methods to warrant its own class.Apologies for the incorrectly clsoed “code” tag above; only
Stateshould be tagged.Note that in python’s heapq module, heappop returns the smallest item. Here we want the state with the largest geomean. So we use -geomean to get the desired ordering.
Interstingly, Montana has the lowest representation, with 1 rep per 989k people, and Rhode Island has the highest, with 1 representative per 526k people.
from heapq import heapify, heappop, heappush from math import sqrt NREPS = 435 popdata = ( ("Alabama", 4779736), ("Alaska", 710231), ("Arizona", 6392017), ("Arkansas", 2915918), ("California", 37253956), ("Colorado", 5029196), ("Connecticut", 3574097), ("Delaware", 897934), ("Florida", 18801310), ("Georgia", 9687653), ("Hawaii", 1360301), ("Idaho", 1567582), ("Illinois", 12830632), ("Indiana", 6483802), ("Iowa", 3046355), ("Kansas", 2853118), ("Kentucky", 4339367), ("Louisiana", 4533372), ("Maine", 1328361), ("Maryland", 5773552), ("Massachusetts", 6547629), ("Michigan", 9883640), ("Minnesota", 5303925), ("Mississippi", 2967297), ("Missouri", 5988927), ("Montana", 989415), ("Nebraska", 1826341), ("Nevada", 2700551), ("New Hampshire", 1316470), ("New Jersey", 8791894), ("New Mexico", 2059179), ("New York", 19378102), ("North Carolina", 9535483), ("North Dakota", 672591), ("Ohio", 11536504), ("Oklahoma", 3751351), ("Oregon", 3831074), ("Pennsylvania", 12702379), ("Rhode Island", 1052567), ("South Carolina", 4625364), ("South Dakota", 814180), ("Tennessee", 6346105), ("Texas", 25145561), ("Utah", 2763885), ("Vermont", 625741), ("Virginia", 8001024), ("Washington", 6724540), ("West Virginia", 1852994), ("Wisconsin", 5686986), ("Wyoming", 563626) ) def geomean(reps, pop): return pop/sqrt(reps*(reps+1)) states = [(-geomean(1, pop), 1, state, pop) for state,pop in popdata] heapify(states) for n in range(NREPS - len(states)): g, reps, state, pop = heappop(states) heappush(states, (-geomean(reps + 1, pop), reps + 1, state, pop)) fmt = "{:2} {:14} {:8} {}" print fmt.format('nr', 'state', 'pop', 'pop/nr') for g, reps, state, pop in sorted(states, key=lambda t:t[1], reverse=True): print fmt.format(reps, state, pop, pop/reps)Not very ruby like in some ways (use of arrays) but pretty darn small …
state_pop_data = [["Alabama", 4779736, 1], ["Alaska", 710231, 1], ["Arizona", 6392017, 1], ["Arkansas", 2915918, 1], ["California", 37253956, 1], ["Colorado", 5029196, 1], ["Connecticut", 3574097, 1], ["Delaware", 897934, 1], ["Florida", 18801310, 1], ["Georgia", 9687653, 1], ["Hawaii", 1360301, 1], ["Idaho", 1567582, 1], ["Illinois", 12830632, 1], ["Indiana", 6483802, 1], ["Iowa", 3046355, 1], ["Kansas", 2853118, 1], ["Kentucky", 4339367, 1], ["Louisiana", 4533372, 1], ["Maine", 1328361, 1], ["Maryland", 5773552, 1], ["Massachusetts", 6547629, 1], ["Michigan", 9883640, 1], ["Minnesota", 5303925, 1], ["Mississippi", 2967297, 1], ["Missouri", 5988927, 1], ["Montana", 989415, 1], ["Nebraska", 1826341, 1], ["Nevada", 2700551, 1], ["New Hampshire", 1316470, 1], ["New Jersey", 8791894, 1], ["New Mexico", 2059179, 1], ["New York", 19378102, 1], ["North Carolina", 9535483, 1], ["North Dakota", 672591, 1], ["Ohio", 11536504, 1], ["Oklahoma", 3751351, 1], ["Oregon", 3831074, 1], ["Pennsylvania", 12702379, 1], ["Rhode Island", 1052567, 1], ["South Carolina", 4625364, 1], ["South Dakota", 814180, 1], ["Tennessee", 6346105, 1], ["Texas", 25145561, 1], ["Utah", 2763885, 1], ["Vermont", 625741, 1], ["Virginia", 8001024, 1], ["Washington", 6724540, 1], ["West Virginia", 1852994, 1], ["Wisconsin", 5686986, 1],["Wyoming", 563626, 1]] def g(p, n) p / Math.sqrt(n * (n+1)) end (1..385).each { state_pop_data[state_pop_data.collect{ |s| g(s[1], s[2]) }.each_with_index.max[1]][2] += 1 } state_pop_data.sort_by!{ |s| -s[2] }.each do |s| puts "#{s[0]} Population = #{s[1]} Representatives: #{s[2]}" endI set the number of representatives to 1 in the initial data. The tricky line is line 23, so let’s step through it. We know we have 385 representatives left so we’ll go through each of them. The next piece is the collect which will generate an array of the g(n, p) values. We then do the each_with_index.max which returns an array of the maximum and the index of the maximum and we grab the index out of the [1] value. We then add 1 to the [2] value (representatives) of the state_pop_data array.
My try in REXX
state_pop = '("Alabama" 4779736) ("Alaska" 710231)', '("Arizona" 6392017) ("Arkansas" 2915918) ("California" 37253956)', '("Colorado" 5029196) ("Connecticut" 3574097) ("Delaware" 897934)', '("Florida" 18801310) ("Georgia" 9687653) ("Hawaii" 1360301)', '("Idaho" 1567582) ("Illinois" 12830632) ("Indiana" 6483802)', '("Iowa" 3046355) ("Kansas" 2853118) ("Kentucky" 4339367)', '("Louisiana" 4533372) ("Maine" 1328361) ("Maryland" 5773552)', '("Massachusetts" 6547629) ("Michigan" 9883640) ("Minnesota" 5303925)', '("Mississippi" 2967297) ("Missouri" 5988927) ("Montana" 989415)', '("Nebraska" 1826341) ("Nevada" 2700551) ("New Hampshire" 1316470)', '("New Jersey" 8791894) ("New Mexico" 2059179) ("New York" 19378102)', '("North Carolina" 9535483) ("North Dakota" 672591) ("Ohio" 11536504)', '("Oklahoma" 3751351) ("Oregon" 3831074) ("Pennsylvania" 12702379)', '("Rhode Island" 1052567) ("South Carolina" 4625364) ("South Dakota" 814180)', '("Tennessee" 6346105) ("Texas" 25145561) ("Utah" 2763885)', '("Vermont" 625741) ("Virginia" 8001024) ("Washington" 6724540)', '("West Virginia" 1852994) ("Wisconsin" 5686986) ("Wyoming" 563626)' sta. = '' pop. = 0 rep. = 1 call build_arrays call assignment call report exit assignment: do i = 1 to 385 max = 0 do j = 1 to 50 geo_mean = pop.j / sqrt(rep.j * (rep.j+1)) if geo_mean > max then do ind = j max = geo_mean end end rep.ind = rep.ind + 1 end return report: say 'Ind State Population Repr.' say copies('-',43) total_reps = 0 do i = 1 to 50 total_reps = total_reps + rep.i aus = overlay(right(i,3),aus,1,3) aus = overlay(sta.i,aus,6,20) aus = overlay(right(pop.i,9),aus,26,9) aus = overlay(right(rep.i,5)sta.i,aus,39,5) say aus end say '' say 'Total of Representatives =' total_reps return build_arrays: ind = 0 do while length(state_pop) > 0 parse value state_pop with '("'state'"'pop')' state_pop ind = ind + 1 sta.ind = state pop.ind = pop end return sqrt: /* z/VM V5R2.0 REXX/VM User's Guide */ arg num xnew = num eps = 0.5 * 10**(1+fuzz()-digits()) do until abs(xold-xnew) < (eps*xnew) xold = xnew xnew = 0.5 * (xold + num / xold) end xnew = xnew / 1 /* strip unnecessary zeros */ return xnewFactor language code. Kind of clunky since heaps are not treated as sequences, so result needs to be converted to an array for printing. Also more stack shuffling than usual is used here.
USING: kernel math math.order math.functions heaps sequences accessors arrays formatting sorting ; IN: house CONSTANT: #seats 435 CONSTANT: state_pop_data { { "Alabama" 4779736 } { "Alaska" 710231 } { "Arizona" 6392017 } { "Arkansas" 2915918 } { "California" 37253956 } { "Colorado" 5029196 } { "Connecticut" 3574097 } { "Delaware" 897934 } { "Florida" 18801310 } { "Georgia" 9687653 } { "Hawaii" 1360301 } { "Idaho" 1567582 } { "Illinois" 12830632 } { "Indiana" 6483802 } { "Iowa" 3046355 } { "Kansas" 2853118 } { "Kentucky" 4339367 } { "Louisiana" 4533372 } { "Maine" 1328361 } { "Maryland" 5773552 } { "Massachusetts" 6547629 } { "Michigan" 9883640 } { "Minnesota" 5303925 } { "Mississippi" 2967297 } { "Missouri" 5988927 } { "Montana" 989415 } { "Nebraska" 1826341 } { "Nevada" 2700551 } { "New Hampshire" 1316470 } { "New Jersey" 8791894 } { "New Mexico" 2059179 } { "New York" 19378102 } { "North Carolina" 9535483 } { "North Dakota" 672591 } { "Ohio" 11536504 } { "Oklahoma" 3751351 } { "Oregon" 3831074 } { "Pennsylvania" 12702379 } { "Rhode Island" 1052567 } { "South Carolina" 4625364 } { "South Dakota" 814180 } { "Tennessee" 6346105 } { "Texas" 25145561 } { "Utah" 2763885 } { "Vermont" 625741 } { "Virginia" 8001024 } { "Washington" 6724540 } { "West Virginia" 1852994 } { "Wisconsin" 5686986 } { "Wyoming" 563626 } } : geomean ( p n -- g ) dup 1 + * sqrt / ; TUPLE: state name pop reps ; : init ( -- heap ) <max-heap> state_pop_data [ first2 1 state boa dup [ pop>> ] [ reps>> ] bi geomean pick heap-push ] each ; : step ( heap -- ) dup heap-pop drop [ name>> ] [ pop>> ] [ reps>> 1 + ] tri 2dup geomean [ state boa ] dip rot heap-push ; : huntington-hill ( heap -- heap ) #seats state_pop_data length - [ dup step ] times ; : extract ( heap -- vec ) V{ } clone swap state_pop_data length [ dup heap-pop drop [ name>> ] [ reps>> ] bi 2array swapd suffix swap ] times drop ; : report ( vec -- ) [ [ second ] bi@ swap <=> ] sort [ first2 "%-20s %d\n" printf ] each ; : house ( -- ) init huntington-hill extract report ;( scratchpad ) house
California 53
Texas 36
New York 27
Florida 27
Illinois 18
Pennsylvania 18
Ohio 16
Michigan 14
Georgia 14
North Carolina 13
New Jersey 12
Virginia 11
Washington 10
….
In F#,
open System open System.Collections.Generic let data = [("Alabama", 4779736,1); ("Alaska", 710231,1); ("Arizona",6392017,1);("Arkansas",2915918,1);("California",37253956,1); ("Colorado",5029196,1);("Connecticut",3574097,1);("Delaware",897934,1); ("Florida",18801310,1);("Georgia",9687653,1);("Hawaii",1360301,1); ("Idaho",1567582,1);("Illinois",12830632,1);("Indiana",6483802,1); ("Iowa",3046355,1);("Kansas",2853118,1);("Kentucky",4339367,1); ("Louisiana",4533372,1);("Maine",1328361,1);("Maryland",5773552,1); ("Massachusetts",6547629,1);("Michigan",9883640,1);("Minnesota",5303925,1); ("Mississippi",2967297,1);("Missouri",5988927,1);("Montana",989415,1); ("Nebraska",1826341,1);("Nevada",2700551,1);("New Hampshire",1316470,1); ("New Jersey",8791894,1);("New Mexico",2059179,1);("New York",19378102,1); ("North Carolina",9535483,1);("North Dakota",672591,1);("Ohio",11536504,1); ("Oklahoma",3751351,1);("Oregon",3831074,1);("Pennsylvania",12702379,1); ("Rhode Island",1052567,1);("South Carolina",4625364,1);("South Dakota",814180,1); ("Tennessee",6346105,1);("Texas",25145561,1);("Utah",2763885,1); ("Vermont",625741,1);("Virginia",8001024,1);("Washington",6724540,1); ("West Virginia",1852994,1);("Wisconsin",5686986,1);("Wyoming",563626,1)] let rec assign data = let totalAssigned = List.sumBy (fun (s,p,n) -> n) data if totalAssigned < 435 then let (s, p, n) = List.maxBy (fun (_, pop, num) -> float(pop) / sqrt (((float)num + 1.0) * (float)num)) data assign ((s,p, n+1) :: (List.filter (fun (x,_,_) -> x <> s) data)) else data |> List.sortBy (fun (_,_,n) -> -n) assign dataIn scala. It could be a bit shorter if I made seats mutable in the State class. Now I have to remove the old State from the List and add the one with the added seat. Not very efficient :)
case class State(name:String, population:Int, seats:Int = 1){ val g = population / scala.math.sqrt(seats * (seats +1)) } object Hor { val states = List(("Alabama", 4779736), ("Alaska", 710231), ("Arizona", 6392017), ("Arkansas", 2915918), ("California", 37253956), ("Colorado", 5029196), ("Connecticut", 3574097), ("Delaware", 897934), ("Florida", 18801310), ("Georgia", 9687653), ("Hawaii", 1360301), ("Idaho", 1567582), ("Illinois", 12830632), ("Indiana", 6483802), ("Iowa", 3046355), ("Kansas", 2853118), ("Kentucky", 4339367), ("Louisiana", 4533372), ("Maine", 1328361), ("Maryland", 5773552), ("Massachusetts", 6547629), ("Michigan", 9883640), ("Minnesota", 5303925), ("Mississippi", 2967297), ("Missouri", 5988927), ("Montana", 989415), ("Nebraska", 1826341), ("Nevada", 2700551), ("New Hampshire", 1316470), ("New Jersey", 8791894), ("New Mexico", 2059179), ("New York", 19378102), ("North Carolina", 9535483), ("North Dakota", 672591), ("Ohio", 11536504), ("Oklahoma", 3751351), ("Oregon", 3831074), ("Pennsylvania", 12702379), ("Rhode Island", 1052567), ("South Carolina", 4625364), ("South Dakota", 814180), ("Tennessee", 6346105), ("Texas", 25145561), ("Utah", 2763885), ("Vermont", 625741), ("Virginia", 8001024), ("Washington", 6724540), ("West Virginia", 1852994), ("Wisconsin", 5686986), ("Wyoming", 563626)).map(x=> State(x._1,x._2)).sortBy(_.g); def divideSeats(states : List[State], seatsLeft:Int) : List[State] = { if(seatsLeft == 0) { return states.sortBy(_.seats * -1); } val max = states.maxBy(_.g) val added = max.copy(seats = max.seats+1) val newStates = added :: states.filter(_.name != max.name) return divideSeats(newStates,seatsLeft-1) } }