More Prime-Counting Functions
July 26, 2011
Don’t be afraid of the Greek letters; you already know 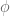
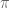
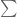

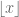
(define (meissel-pi n)
(if (< n max-pi) (pi n)
(let ((b (pi (isqrt n))) (c (pi (iroot 3 n))))
(let loop ((i (+ c 1)) (sum (+ (phi n c) (quotient (* (+ b c -2) (- b c -1)) 2))))
(if (< b i) sum
(loop (+ i 1) (- sum (pi (quotient n (p i))))))))))
Lehmer’s formula isn’t much harder:
(define (lehmer-pi n)
(if (< n max-pi) (pi n)
(let ((a (pi (iroot 4 n))) (b (pi (isqrt n))) (c (pi (iroot 3 n))))
(let i-loop ((i (+ a 1)) (sum (+ (phi n a) (quotient (* (+ b a -2) (- b a -1)) 2))))
(if (< b i) sum
(let* ((w (quotient n (p i))) (lim (pi (isqrt w))) (sum (- sum (pi w))))
(if (< c i) (i-loop (+ i 1) sum)
(let j-loop ((j i) (sum sum))
(if (< lim j) (i-loop (+ i 1) sum)
(j-loop (+ j 1) (- sum (pi (quotient w (p j))) (- j) 1)))))))))))
A library function to compute integer roots is given in the codepad source, which also includes all the code from the previous exercise. Our timing comparisons show that each successive function is about an order of magnitude faster than the previous one; in each case, we cleared the cache in the phi function, then computed each value in order:
legendre meissel lehmer (prime-pi n)
10^0 0.000 0.000 0.000 0
10^1 0.000 0.000 0.000 4
10^2 0.000 0.000 0.000 25
10^3 0.000 0.000 0.000 168
10^4 0.002 0.000 0.000 1229
10^5 0.010 0.002 0.002 9592
10^6 0.072 0.012 0.005 78498
10^7 0.739 0.059 0.021 664579
10^8 3.836 0.509 0.089 5761455
10^9 41.932 2.626 0.791 50847534
10^10 --- 12.579 2.163 455052511
10^11 --- 124.483 13.539 4118054813
10^12 --- --- 125.810 37607912018
The timings were done on a recent-vintage personal computer, running Petite Chez Scheme on Linux.

I think your write-up of Lehmer’s formula on the first page doesn’t match your code on the second. Specifically, what is
b_isupposed to be? And is the fraction out front(b + a - 2) * (b - a + 1) / 2or(b + c - 2) * (b - c + 1) / 2?Oops. I didn’t do that very well, did I? It’s now fixed.
b_i = pi(isqrt(x/p_i) for a<i<=c
The fraction is (b+a-2)(b-a+1)/2
I’m completely off my game; Python is either giving me nonsense or complaining of exceeding the recursion depth. I’m going to start over, so I won’t have a solution for a bit.
In Lehmer’s formula, it should be \phi(x, a). It looks like your program does the right thing. I just set a = c for Meissel, then it becomes a small change from Lehmer — just remove the last double summation (and obviously a and c are different).
I don’t know if the formatting will work — crossing fingers.
Code: lehmer.c on github
alternate: link to exponent vs. log time graph
I wrote this over the last couple weeks as part of the Perl module Math::Prime::Util module, where it’s given a very nice speedup for prime_count and nth_prime. I decided to go ahead and make it work as a standalone program using primesieve, and add the Meissel formula. Thanks to this blog for giving me the added impetus to do it.
I use primesieve with its parallel siever, which means given 12 cores (6 + hyperthreading) it’s very fast. I don’t use parallelism anywhere else in the program, which is one reason why Legendre comes out so bad compared to straight sieving. We’re comparing my serial phi(x,a) code to primesieve’s optimized sieving. Also, I use primesieve for some of the large segment sieves at the end of the Lehmer and Meissel calculations. In theory I could recurse to get these values, but given, for example: Pi(5620819515485) when we just calculated the result of Pi(5615769079576), it’s a lot faster to just ask for the primes in that range.
The phi(x,a) calculation is an interesting exercise. Given that I want a program to work for n = 10^18 or higher, using simple recursion is not going to cut it. At some point space becomes as important as speed, and simple memoization won’t cut it either with hundreds of millions of unique x,a pairs. The solution I came up with was to walk down ‘a’ values holding a list of the current ‘x’ values for this ‘a’. It became clear that many of these values are identical, so we can coalesce them into a single unique ‘x’ and a signed count. At any point we’re only storing the unique ‘x’ values and a count for a single ‘a’ value. In Perl I used two hashes, while my solution in C is two heaps. augmented with small arrays to help performance at the bottom end where it becomes dense (that is, we will end up with a non-zero count for basically every ‘x’ value below some threshold). I still feel like this could be improved — two obvious non-optimal things are (1) it coalesces similar ‘x’ values on removal rather than insertion, and (2) two heaps are used while in theory we only need as much total memory as the largest one. #1 could be solved using an ordered list, though noting that anything using pointers per element is probably a non-starter just from memory use, but buckets might work. A good way to parallize the phi calculation would be nice also.
With Math::Prime::Util’s non-parallel segmented siever, the phi(x,a) calculation takes about 15% of the total time, which is a heck of a lot less than it was when I started. Using primesieve’s parallel and optimized sieving, it comes out nearer to 50% (in other words, primesieve in parallel makes the final stage (the summations) run ~10x faster than MPU in serial). There are different tradeoffs that could be made here — more memory spent on “small” primes would mean less time doing segment sieves. Parallelizing the loops would help MPU. Running the phi(x,a) calculation in parallel with the last stage is possible and could give a nice spsedup, but it would nearly double memory use, which is definitely a bad thing.
Table of raw times in seconds:
Sieve Legendre Meissel Lehmer 10^5 0.00141 0.00174 0.00285 0.00388 10^6 0.00161 0.00344 0.00306 0.0012 10^7 0.00378 0.01198 0.00358 0.00156 10^8 0.00775 0.04193 0.00555 0.00329 10^9 0.03724 0.32352 0.01652 0.01853 10^10 0.34622 2.72898 0.07415 0.03533 10^11 4.15675 22.83046 0.34653 0.12613 10^12 50.52079 195.34312 1.82301 0.57864 10^13 610.47052 1707.51764 9.36845 2.82593 10^14 49.90988 13.97931 10^15 289.39294 70.68814 10^16 1733.79125 354.63109 10^17 1767.91606Again, ‘Sieve’ is primesieve in parallel on 12 cores. Time growth is about a factor of 12x for each 10x larger range. For Legendre (completely serial — all time is spent in phi), growth is 8-9x. Meissel is 5-6x, Lehmer is 5x. When I did a fit on an earlier version with Lehmer using MPU last week it came out to c * x ^ 0.72 which is pretty close to where it should be (10^0.7 = 5.01 so it looks like Lehmer with primesieve is right on the money). One interesting point is how in your Scheme timings, Legendre was not much more than an order of magnitude slower than Meissel. While the absolute results for my Meissel vs. Lehmer are faster, the ratios aren’t that far off. Legendre is far, far off however. My guess is that Legendre is stuck doing a giant phi calculation in both cases, while in your Scheme code you have each prime count in the summations do recursive calls (assuming they’re larger than max-pi). There are two optimizations I made there: (1) if we generate just a few more primes than we needed for the prime[i] values in the summation loops, we can use a binary search to cut out a lot of the smaller calls, and (2) arrange the summation loop so it decrements i means the w values end up in increasing order, so we can use a segment sieve to just count the values between the previous call and the current one.
I haven’t tried, but I suspect memory constraints in the phi calculation are going to limit my program to not much more than 10^18, unless I buy more memory. I’m a little intrigued by how well running this offline using GMP and distributing the computations would work, but I suspect it still would be just too slow to be of any interest other than personal.
Fixed. Thank you.