House Of Representatives
April 12, 2011
The United States counts its citizens every ten years, and the result of that census is used to allocate the 435 congressional seats in the House of Representatives to the 50 States. Since 1940, that allocation has been done using a method devised by Edward Huntington and Joseph Hill that minimizes percentage differences in the sizes of the congressional districts.
The Huntington-Hill method begins by assigning one representative to each State. Then each of the remaining representatives is assigned to a State in a succession of rounds by computing 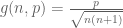
For instance, once each State has been assigned one representative, the geometric mean g(n, p) for each State is its population divided by the square root of 2. Since California has the biggest population, it gets the 51st representative. Then its geometric mean is recalculated as its population divided by the square root of 2 × 3 = 6, and in the second round the 52nd representative is assigned to Texas, which has the second-highest population, since it now has the largest geometric mean g(n, p). This continues for 435 − 50 = 385 rounds until all the representatives have been assigned.
Your task is to compute the apportionment of seats in the House of Representatives; the population data is given on the next page. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Credit Card Validation
April 8, 2011
Most credit card numbers, and many other identification numbers including the Canadian Social Insurance Number, can be validated by an algorithm developed by Hans Peter Luhn of IBM, described in U. S. Patent 2950048 in 1954 (software patents are nothing new!), and now in the public domain. The Luhn algorithm will detect almost any single-digit error, almost all transpositions of adjacent digits except 09 and 90, and many other errors.
The Luhn algorithm works from right-to-left, with the right-most digit being the check digit. Alternate digits, starting with the first digit to left of the check digit, are doubled. Then the digit-sums of all the numbers, both undoubled and doubled, are added. The number is valid if the sum is divisible by ten.
For example, the number 49927398716 is valid according to the Luhn algorithm. Starting from the right, the sum is 6 + (2) + 7 + (1 + 6) + 9 + (6) + 7 + (4) + 9 + (1 + 8) + 4 = 70, which is divisible by 10; the digit-sums of the doubled digits have been shown in parentheses.
Your task is to write two functions, one that adds a check digit to a identifying number and one that tests if an identifying number is valid. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Fortune
April 5, 2011
We have today another in our occasional series of re-implementations of Unix V7 commands. The fortune command prints a random aphorism on the user’s terminal; many people put the fortune command in their login script so they get a new aphorism every time they login. Here’s the man page:
NAME
fortune
SYNOPSIS
fortune [ file ]
DESCRIPTION
Fortune prints a one-line aphorism chosen at random. If a file is specified, the sayings are taken from that file; otherwise they are selected from /usr/games/lib/fortunes.
FILES
/usr/games/lib/fortunes - sayings
The fortunes are stored in a file, one fortune per line. The original Unix V7 fortunes file, available from http://minnie.tuhs.org/cgi-bin/utree.pl?file=V7/usr/games/lib/fortunes, is reproduced at the end of the exercise.
Your task is to implement the Unix V7 fortune program. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Maximum Difference In An Array
April 1, 2011
Today’s problem is this:
Given an array X, find the j and i that maximizes Xj − Xi, subject to the condition that i ≤ j. If two different i,j pairs have equal differences, choose the “leftmost shortest” pair with the smallest i and, in case of a tie, the smallest j.
For instance, given an array [4, 3, 9, 1, 8, 2, 6, 7, 5], the maximum difference is 7 when i=3 and j=4. Given the array [4, 2, 9, 1, 8, 3, 6, 7, 5], the maximum difference of 7 appears at two points, but by the leftmost-shortest rule the desired result is i=1 and j=2. I and j need not be adjacent, as in the array [4, 3, 9, 1, 2, 6, 7, 8, 5], where the maximum difference of 7 is achieved when i=3 and j=7. If the array is monotonically decreasing the maximum difference is 0, which by the leftmost-shortest rule occurs when i=0 and j=0.
There are at least two solutions. The obvious solution that runs in quadratic time uses two nested loops, the outer loop over i from 0 to the length of the array n and the inner loop over j from i+1 to n, computing the difference between Xi and Xj and saving the result whenever a new maximum difference is found. There is also a clever linear-time solution that traverses the array once, simultaneously searching for a new minimum value and a new maximum difference; you’ll get it if you think about it for a minute.
Your task is to write both the quadratic and linear functions to compute the maximum difference in an array, and also a test function that demonstrates they are correct. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Look And Say, Revisited
March 28, 2011
We calculated the look and say sequence in a previous exercise, and mentioned there that the sequence has some fascinating mathematical properties. One of them is that, if Ln is the number of digits in the n-th element of the sequence, then

where λ is known as Conway’s constant, calculated by the British mathematician John Horton Conway as the unique positive real root of the following polynomial:

Conway analyzed the look and say sequence in his paper “The Weird and Wonderful Chemistry of Audioactive Decay” published in Eureka, Volume 46, Pages 5−18 in 1986. In his blog, Nathaniel Johnston gives a derivation of the polynomial.
Your task is to compute the value of λ. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Sum
March 25, 2011
Today’s exercise implements the old Unix Sys V R4 sum command. The original sum calculated a checksum as the sum of the bytes in the file, modulo 216−1, as well as the number of 512-byte blocks the file occupied on disk. Called with no arguments, sum read standard input and wrote the checksum and file blocks to standard output; called with one or more filename arguments, sum read each file and wrote for each a line containing the checksum, file blocks, and filename. The GNU version of the program, which implements an additional version of the checksum that was part of BSD Unix, is available at ftp://alpha.gnu.org/gnu/coreutils/textutils-2.0.22.tar.gz in file sum.c; if you run it, be sure to give the −s argument to get the original Unix Sys V R4 version of the checksum.
Your task is to write a program that implements the original Unix Sys V R4 sum command. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Two Kaprekar Exercises
March 22, 2011
For today’s exercise we return to the world of recreational mathematics with two exercises due to the Indian mathematician Dattaraya Ramchandra Kaprekar. First we compute Kaprekar chains:
1. Choose any four-digit number, with at least two different digits. Leading zeros are permitted.
2. Arrange the digits into two numbers, one with the digits sorted into ascending order, the other with the digits sorted into descending order.
3. Subtract the smaller number from the larger number.
4. Repeat until the number is 6174. At that point, the process will cycle with 7641 − 1467 = 6174.
For instance, starting with 2011, the chain is 2110 − 112 = 1998, 9981 − 1899 = 8082, 8820 − 288 = 8532, and 8532 − 2358 = 6174.
The second exercise determines if a number is a Kaprekar number, defined as an n-digit number such that, when it is squared, the sum of the first n or n−1 digits and the last n digits is the original number. For instance, 703 is a Kaprekar number because 7032 = 494209 and 494 + 209 = 703. Sloane gives the list of Kaprekar numbers at A053816.
Your task is twofold: first, write a program that computes the Kaprekar chain for a given starting number, and compute the longest possible Kaprekar chain; second, write a program to determine if a particular number is a Kaprekar number, and compute the list of all the Kaprekar numbers less than a thousand. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Loopy Loops
March 18, 2011
I don’t like this silly question. But it has appeared recently on Hacker News and Stack Overflow (C/C++ and Java, and probably other languages but I quit searching), and generated lots of comments on both, and it’s apparently a popular interview question, so we may as well do it here, too:
Print the numbers from 1 to 1000 without using any loop or conditional statements. Don’t just write the printf() or cout statement 1000 times.
Your task is to write the program in your favorite language. Have fun — think of as many solutions as you can, or the wackiest, or the fewest characters in the source file, or some other best-in-category. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Look And Say
March 15, 2011
The “Look and Say” sequence, Sloane number A005150, begins 1, 11, 21, 1211, 111221, 312211, 13112221, 1113213211, …. Each term is constructed from its predecessor by stating the frequency and number of each group of like digits. For instance, the term after 1211 is “one 1, one 2, and two 1s”, or 111221. This sequence was studied by the British mathematician John Horton Conway, and has some fascinating properties; see MathWorld or follow the references at Sloane’s if you are interested.
Your task is to write a program to compute the look and say sequence. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Lowest Common Ancestor
March 11, 2011
 Today’s problem appears with some regularity at places like Proggit and Stack Overflow and in lists of programming interview questions:
Today’s problem appears with some regularity at places like Proggit and Stack Overflow and in lists of programming interview questions:
Given a binary tree t and two elements of the tree, m and n, with m<n, find the lowest element of the tree (farthest from the root) that is an ancestor of both m and n.
For example, in the tree shown at right, the lowest common ancestor of 4 and 7 is 6, the lowest common ancestor of 4 and 10 is 8, and the lowest common ancestor of 1 and 4 is 3. It is possible for an element of the tree to be its own ancestor, so the lowest common ancestor of 1 and 3 is 3, and the lowest common ancestor of 3 and 6 is 3.
Your task is to write a function that finds the lowest common ancestor of two elements of a binary tree. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
