A Golden Exercise
July 12, 2009
 The exercise that will be published on Tuesday will be the fiftieth exercise published at Programming Praxis, marking our Golden Anniversary. My thanks to all you readers, and especially those who contributed code and other comments, for making this blog special. I am always delighted to hear from my readers, especially if they are contributing an idea for an exercise (hint, hint). It’s a lot of fun writing these exercises, but also a lot of work, and your contributions make it worthwhile. <grin>I can tell that the blog is starting to be successful because spam comments, which I must delete manually, now exceed ham comments.</grin>
The exercise that will be published on Tuesday will be the fiftieth exercise published at Programming Praxis, marking our Golden Anniversary. My thanks to all you readers, and especially those who contributed code and other comments, for making this blog special. I am always delighted to hear from my readers, especially if they are contributing an idea for an exercise (hint, hint). It’s a lot of fun writing these exercises, but also a lot of work, and your contributions make it worthwhile. <grin>I can tell that the blog is starting to be successful because spam comments, which I must delete manually, now exceed ham comments.</grin>
Tuesday’s exercise will also introduce a change in the structure of the exercises. The suggested solution will be on a separate page published forty-eight hours after the exercise. That gives regular readers a chance to work on their own solutions without being influenced by the suggested solution. Comments will be attached to the exercise, not the solution.
Our first fifty exercises have developed several themes: related sequences of exercises involving prime numbers and cryptography, exercises in data structures like ternary search tries and exercises in algorithms like modular arithmetic, some exercises simple and others not-quite-so simple, and puzzles like sudoku and Feynman. The next fifty exercises will be more of the same, featuring some new sequences of related exercises, some old friends, and the odd puzzle or two. And I am always open to suggestions!
To celebrate our Golden Anniversary, Tuesday’s exercise will be somewhat more ambitious than normal, so get those compilers revving. Happy coding! And please enjoy a piece of virtual anniversary cake!
And now, may I ask for your help. I would like to move the site from wordpress.com to its own host, still running WordPress software, so that I can finally fix the theme and, more importantly, automate some processes that I am currently doing by hand (and some others I am not doing at all). But I have never blogged before, and have no experience with hosting, or migrating a domain registration, or maintaining a WordPress installation. If some reader would like to offer advice, please contact me at programmingpraxis@gmail.com.
The Golden Ratio
July 10, 2009
I was helping my daughter with her math homework recently, and came across this problem in continued fractions:
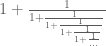
This fraction can be considered as a sequence of terms


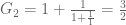
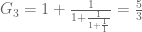
Or, in general

The first ten elements of the sequence are 1, 2, 3/2, 5/3, 8/5, 13/8, 21/13, 34/21, 55/34, and 89/55.
Your task is to write a program that evaluates the nth element of the sequence. What is the value of 
Modular Arithmetic
July 7, 2009
Modular arithmetic is a branch of number theory that is useful in its own right and as a tool in such disciplines as integer factorization, calendrical and astronomical calculations, and cryptography. Modular arithmetic was systematized by Carl Friedrich Gauss in his book Disquisitiones Arithmeticae, published in 1801.
Modular arithmetic is a system of arithmetic for integers in which all results are expressed as non-negative integers less than the modulus. A familiar use of modular arithmetic is the twelve-hour clock, in which eight hours after nine o’clock is five o’clock; that is, 9 + 8 ≡ 5 (mod 12). The ≡ sign used in modular arithmetic specifies congruence, not equality. Two numbers are congruent in a given modulus if the difference between them is an even multiple of the modulus; for instance 17 ≡ 5 (mod 12). Modular addition is like regular addition, but “wraps around” at the modulus. Modular subtraction is the inverse operation of modular addition, and modular multiplication is just repeated modular addition; for instance 4 − 9 ≡ 7 (mod 12), and 3 × 7 ≡ 9 (mod 12).
Modular division is the inverse operation of modular multiplication, just as regular division is the inverse operation of regular multiplication. In modular arithmetic, the modular inverse of an integer p is that integer q for which p × q ≡ 1 (mod n); the modular inverse is undefined, just as division by zero is undefined, unless the target number is coprime to the modulus. The extended Euclidean algorithm calculates the inverse; given ax + by = g = gcd(x, y), when g = 1 and x > 0, b (mod x) and a (mod y) are the inverses of y (mod x) and x (mod y), respectively. Then modular division is just modular multiplication by the inverse. For instance, 9 ÷ 7 ≡ 3 (mod 12).
Exponentiation in modular arithmetic is repeated modular multiplication, just as exponentiation is repeated multiplication in normal arithmetic. Modular exponentiation could be performed by first computing the exponentiation and then performing the modulo operation, but that could involve a large intermediate result. A better method performs the modulo operations at each multiplication, squaring when possible to reduce the number of intermediate multiplications.
Square root is defined in modular arithmetic as that number which, when multiplied by itself, equals the target number, just as in normal arithmetic. And just as in normal arithmetic, every square root has a conjugate on the “other side” of zero, except that in modular arithmetic there is no “other side” of zero, so the two conjugates are the negatives of each other, adding to the modulus. For instance the square roots of 18 (mod 31) are 7 and 24, since 7 × 7 ≡ 18 (mod 31) and 24 × 24 ≡ 18 (mod 31), and 7 + 24 = 31.
Square root is a more difficult concept in modular arithmetic than regular arithmetic, because there are many cases where the modular square root does not exist. For instance, consider the squares x2 (mod 13), 0 ≤ x < 13: 0, 1, 4, 9, 3, 12, 10, 10, 12, 3, 9, 4, 1. There is no number that can be squared modulo 13 to evaluate to 7, so the square root of 7 modulo 13 does not exist; the only numbers that have square roots modulo 13 are 1, 3, 4, 9, 10, and 12, or, equivalently, ±1, ±3, and ±4. Another restriction is that the modular square root is only defined if the modulus is an odd prime. For instance, consider the squares x2 (mod 15), 0 ≤ x < 15: 0, 1, 4, 9, 1, 10, 6, 4, 4, 6, 10, 1, 9, 4, 1. The number 4 has two sets of conjugate square roots: ±2 and ±7. Since the solution is not unique, the modular square root can be said not to exist when the modulus is composite.
If you need a refresher on the math that supports modular arithmetic, you can look at any number theory textbook, or search the internet for terms such as modular arithmetic, bezout identity, modular inverse, jacobi symbol, and quadratic residue.
Your task is to write a library that provides convenient access to the basic operations of modular arithmetic: addition, subtraction, multiplication, division, exponentiation, and square root. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
The Playfair Cipher
July 3, 2009
One of the most famous of the classical ciphers was the Playfair cipher, invented by Sir Charles Wheatstone in 1854 but popularized by Lord Lyon Playfair. The cipher was used by the British during the Boer War and World War I, and was still in use as a field-grade cipher as late as World War II, probably because it is simple to teach, fast to use, requires no special equipment, and was reasonably secure by the standards of the day; by the time enemy cryptanalysts could break the message, its contents were useless to them.
Playfair uses a 5-square block containing the pass-phrase; the letter J is mapped to I to make the 26-letter alphabet fit the 5-square block. The pass-phrase is first filled in to the 5-square block, then the remaining letters of the alphabet complete the 5-square block, with duplicates removed. For instance, the pass-phrase PLAYFAIR leads to this 5-square block:
P L A Y F
I R B C D
E G H K M
N O Q S T
U V W X Z
Some variants of Playfair omit Q instead of J, or start the key from the bottom-right corner and work backwards; we’ll stick with the standard method.
The message to be encrypted is split into digrams, with J mapped to I. In addition, no digram may use the same letter twice, so an X is inserted if needed (some Playfair variants use Z or Q instead of X). Likewise, if the last digram has only a single letter, an X is added to the end of the message. For instance, the plain-text PROGRAMMING PRAXIS is split as:
PR OG RA MX MI NG PR AX IS
Then each digram is enciphered separately according to the following rules:
- If the two letters of the digram are in the same row, they are replaced pairwise by the letters to their immediate right, wrapping around to the left of the row if needed.
- If the two letters of the digram are in the same column, they are replaced pairwise by the letters immediately below, wrapping around to the top of the column if needed.
- Otherwise, the first letter of the digram is replaced by the letter in the same row as the first letter of the digram and the same column as the second letter of the digram, and the second letter of the digram is replaced by the letter in the same row as the second letter of the digram and the same column as the first letter of the digram.
For instance, the PR digram is enciphered as LI, because P and R are in different rows and columns, and the OG digram is enciphered as VO, since O and G are in the same column. The complete encipherment is shown below:
PR OG RA MX MI NG PR AX IS
LI VO BL KZ ED OE LI YW CN
The coded message is thus LIVOBLKZEDOELIYWCN. Decryption is simply the inverse of encryption.
Playfair is rather more secure than simpler substitution ciphers because it works with digrams rather than single letters, rendering simple frequency analysis moot. Frequency analysis on digrams is possible, but requires considerably more cipher-text than frequency analysis on single letters because Playfair admits 600 digrams whereas simple substitution admits only 26 letters. Manual cryptanalysis looks at commonly-reversed digrams such as REceivER and DEcodED; if some plain-text is known (such as a standard message header), it is easy to recover at least a partial key.
The most famous use of the Playfair cipher came in 1943. David Kahn writes in The Codebreakers:
Perhaps the most famous cipher of 1943 involved the future president of the U.S., J. F. Kennedy, Jr. On 2 August 1943, Australian Coastwatcher Lieutenant Arthur Reginald Evans of the Royal Australian Naval Volunteer Reserve saw a pinpoint of flame on the dark waters of Blackett Strait from his jungle ridge on Kolombangara Island, one of the Solomons. He did not know that the Japanese destroyer Amagiri had rammed and sliced in half an American patrol boat PT-109, under the command of Lieutenant John F. Kennedy, United States Naval Reserve. Evans received the following message at 0930 on the morning of the 2 of August 1943:
KXJEY UREBE ZWEHE WRYTU HEYFS
KREHE GOYFI WTTTU OLKSY CAJPO
BOTEI ZONTX BYBWT GONEY CUZWR
GDSON SXBOU YWRHE BAAHY USEDQThe translation:
PT BOAT ONE OWE NINE LOST IN ACTION IN BLACKETT
STRAIT TWO MILES SW MERESU COVE X CREW OF TWELVE
X REQUEST ANY INFORMATION.The coastwatchers regularly used the Playfair system. Evans deciphered it with the key ROYAL NEW ZEALAND NAVY and learned of Kennedy’s fate. […] About ten hours later, at 10:00 p.m. Kennedy and his crew was rescued.
Your task is to write functions that encipher and decipher messages using the Playfair cipher. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Steve Yegge’s Phone-Screen Coding Exercises
June 30, 2009
Steve Yegge is a programmer and popular blogger. One of his blog entries proposes these seven phone-screen coding exercises:
- Write a function to reverse a string.
- Write a function to compute the Nth fibonacci number.
- Print out the grade-school multiplication table up to 12 x 12.
- Write a function that sums up integers from a text file, one per line.
- Write a function to print the odd numbers from 1 to 99.
- Find the largest int value in an int array.
- Format an RGB value (three 1-byte numbers) as a 6-digit hexadecimal string.
Your task is to write solutions to stevey’s phone-screen exercises. When you are finished, you are welcome to read a suggested solution, or to post your solution or discuss the exercise in the comments below.
Treaps
June 26, 2009
Dictionaries are a common data type, which we have used in several exercises (Mark V. Shaney, Word Frequencies, Dodgson’s Doublets, Anagrams). Hash tables are often used as the underlying implementation for dictionaries, and in a previous exercise we developed ternary search tries as another implementation for dictionaries, which are useful when the keys are strings. Today’s exercise examines treaps, which are yet another method for implementing dictionaries.
A treap is essentially a binary search tree, represented as either an empty node, called nil, or a node with a key and a value and pointers to two child nodes, the left child and the right child. Binary search trees obey the rule that all nodes in the left child have keys that are less than the key of the current node, and all nodes in the right child have keys that are greater than the key of the current node. One node is distinguished as the root of the tree; it is the only node visible outside the tree. Obviously, a single set of keys could be represented by many different binary search trees, depending on which key is chosen as the root and the choices made at each level under the root.
The speed of a search depends on the depth at which the key is located in the tree. Trees that have more balance (fewer nodes with nil children) are faster to search than trees that have less balance (more nodes with nil children) because the overall depth of the tree is less. The two extreme cases occur when a tree is perfectly balanced (no internal nil nodes), when a search takes time logarithmic in the size of the tree, and when a tree is perfectly imbalanced (a long chain of nodes each with one nil child), when a search takes time linear in the size of the tree.
Treaps use an ingenious method to assure that the tree is approximately balanced at all times. Each node, in addition to the key, value, and two child nodes, contains a numeric priority, which is randomly assigned at the time the node is created and never changed. Of the many possible trees that could represent a particular set of keys, the one that is chosen obeys the heap-order property, with the priority of each node being greater than the priorities of all of its child nodes. Assuming all keys and priorities are distinct, there will be exactly one tree that satisfies both the tree-order and heap-order properties; it is the same tree that would be created if keys were dynmically inserted into a normal binary search tree in order of the priority field. The genius of this method is that the priorities are independent of the keys, making it extremely unlikely that highly-imbalanced trees could be created, thus keeping search times approximately logarithmic.
As nodes are dynamically inserted into and deleted from the tree, it is sometimes necessary to restructure the tree to maintain both the tree-order and the heap-order properties. The restructurings, known as rotations, come in two varieties, left and right:

[ This image, by Ramasamy, is used under the terms of the GNU Free Documentation License or the Creative Commons Attribution Share-Alike License. ]
In both trees shown above, all the nodes in sub-tree A have keys less than p, all the nodes in sub-tree B have keys between p and q, and all the nodes in sub-tree C have keys greater than q. Transforming the tree so that the root moves from p to q is called a left rotation, and transforming the tree so that the root moves from q to p is called a right rotation; in both cases the root node moves down the tree toward the leaves. Note that both rotations preserve the tree-order property. It is the goal of the insert and delete algorithms to use rotations to maintain the heap-order property.
Your task is to implement the lookup, insert, update, delete and enlist operations on treaps. When you are finished, you are welcome to read or run a suggested solution, or post your solution or discuss the exercise in the comments below.
The Mod Out System
June 23, 2009
Over at The Daily WTF, Alex Papadimoulis catalogs some insanely bad programming practices. The Mod Out System is one of the best … worst … absolutely sickening … no boss, I would never do such a thing … well, you get the point.
The hero of the story, Gary, must write a function to expand a list of ranges like 1-6,9,13-19 into a list without ranges like 1,2,3,4,5,6,9,13,14,15,16,17,18,19.
Your task is to write that function. When you are finished, you are welcome to read or run a suggested solution, or to post your solution or discuss the exercise in the comments below.
Monte Carlo Factorization
June 19, 2009
We have previously examined two methods of integer factorization, trial division using wheels and Fermat’s method of the differences of squares. In this exercise we examine a probabilistic method of integer factorization that takes only a small, fixed amount of memory and tends to be very fast. This method was developed by John Pollard in 1975 and is commonly called the Pollard rho algorithm.
The algorithm is based on the observation that, for any two random integers x and y that are congruent modulo p, the greatest common divisor of their difference and n, the integer being factored, will be 1 if p and n are coprime (have no factors in common) but will be between 1 and n if p is a factor of n. By the birthday paradox, p will be found with reasonably large probability after trying about 
Pollard’s algorithm uses a function modulo n to generate a pseudo-random sequence. Two copies of the sequence are run, one twice as fast as the other, and their values are saved as x and y. At each step, we calculate gcd(x–y,n). If the greatest common divisor is one, we loop, since the two values are coprime. If the greatest common divisor is n, then the values of the two sequences have become equal and Pollard’s algorithm fails, since the sequences have fallen into a cycle, which is detected by Floyd’s tortoise-and-hare cycle-finding algorithm; that’s why we have two copies of the sequence, one (the “hare”) running twice as fast as the other (the “tortoise”). But if the greatest common divisor is between 1 and n, we have found a factor of n.
Failure doesn’t mean failure. It just means that the particular pseudo-random sequence that we chose doesn’t lead to success. Our response to failure is to try another sequence. We use the function x² + c (mod n), where c is initially 1. If Pollard’s algorithm fails, we increase c to 2, then 3, and so on. If we keep increasing c, we will eventually find a factor, though it may take a long time if n is large.
Your task is to implement Pollard’s factorization algorithm. You can test it by calculating the factors of the 98th Mersenne number, 298 – 1. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
We’re moving and changing!
June 17, 2009
Programming Praxis has a new web address: programmingpraxis.com. For the moment, Programming Praxis is still hosted at wordpress.com, so the old address at programmingpraxis.wordpress.com will still work (it maps the old address to the new address), but that will change sometime in the future. Please update your bookmarks. The RSS feed moves to programmingpraxis.com/feed. All existing content, including your comments, remains.
Programming Praxis also has a new theme, and a logo, which was designed by Remco Niemeijer. Thanks, Remco! Some of the pages have moved, others will be moving shortly, some will change, and there will soon be some new additions.
Thanks to all my readers for their patience during this transition. Please let me know if you see anything that breaks, or if you have suggestions for other changes. You can contact me at programmingpraxis@gmail.com.
Who Owns The Zebra?
June 16, 2009
This famous puzzle was first published by Life magazine on December 17, 1962. It has been variously attributed to both Albert Einstein and Lewis Carroll, but the true author is not known. There are several versions; this is the original from Life:
1 There are five houses.
2 The Englishman lives in the red house.
3 The Spaniard owns the dog.
4 Coffee is drunk in the green house.
5 The Ukrainian drinks tea.
6 The green house is immediately to the right of the ivory house.
7 The Old Gold smoker owns snails.
8 Kools are smoked in the yellow house.
9 Milk is drunk in the middle house.
10 The Norwegian lives in the first house.
11 The man who smokes Chesterfields lives in the house next to the man with the fox.
12 Kools are smoked in the house next to the house where the horse is kept.
13 The Lucky Strike smoker drinks orange juice.
14 The Japanese smokes Parliaments.
15 The Norwegian lives next to the blue house.
In the interest of clarity, it must be added that each of the five houses is painted a different color, and their inhabitants are of different national extractions, own different pets, drink different beverages and smoke different brands of American cigarettes.
Your task is to write a program to solve the puzzle and determine: Who drinks water? Who owns the zebra? When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.

{kind=link}