Fermat’s little theorem states that for any prime number 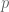 , and any other number
, and any other number  ,
,  . Rearranging terms, we have
. Rearranging terms, we have  , which means that divides the left-hand side of the equation, thus is a factor of the left-hand side.
, which means that divides the left-hand side of the equation, thus is a factor of the left-hand side.
John Pollard used this idea to develop a factoring method in 1974. His idea is to choose a very large number and see if it has any factors in common with  , thus giving a factor of . A systematic way to test many very large numbers is by taking large factorials, which have many small factors within them. Thus, Pollard’s
, thus giving a factor of . A systematic way to test many very large numbers is by taking large factorials, which have many small factors within them. Thus, Pollard’s 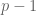 factorization algorithm is this:
factorization algorithm is this:
1) Choose 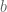 , which is known as the smoothness bound, and calculate the product of the primes to by
, which is known as the smoothness bound, and calculate the product of the primes to by  .
.
2) Choose a random integer such that 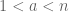 .
.
3) Calculate  . If
. If  is strictly greater than 1, then it is a non-trivial factor of
is strictly greater than 1, then it is a non-trivial factor of  . Otherwise, continue to the next step.
. Otherwise, continue to the next step.
4) Calculate  . If
. If  , then
, then 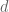 is a non-trivial factor of . If
is a non-trivial factor of . If  , go to Step 1 and choose a larger . If
, go to Step 1 and choose a larger . If 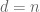 , go back to Step 2 and choose another .
, go back to Step 2 and choose another .
In Step 4, you can quit with failure instead of returning to Step 1 if becomes too large, where “too large” is probably somewhere around  ; in that case, you will need to continue with some other factoring algorithm.
; in that case, you will need to continue with some other factoring algorithm.
Your task is to write a function that factors integers by Pollard’s method. What are the factors of  ? When you are finished, you are welcome to read or run a suggested solution, or to post your solution or discuss the exercise in the comments below.
? When you are finished, you are welcome to read or run a suggested solution, or to post your solution or discuss the exercise in the comments below.
Pages: 1 2

I wrote a prolog implementation ,which works now and then :), but not
always,most of the time it says ‘out of local stack’.
So i saved the result, factors are [4432676798593, 4363953127297, 127, 43, 3].
I would love to see the prolog code for the above problem.
a must be coprime to p, not any other number.
[…] have studied John Pollard’s p−1 algorithm for integer factorization on two previous occasions, giving first the basic single-stage algorithm and later adding a second stage. In […]
all_factorsrepeatedly applies a factorizing methodfactorton:let all_factors factor n = let open Big_int in let rec go l n = if le_big_int n unit_big_int then l else if is_even_big_int n then go (two_big_int :: l) (shift_right_big_int n 1) else if is_prime n then (n :: l) else let f = factor n in go (go l f) (div_big_int n f) in List.sort compare_big_int (go [] n)Besides
modexp_big_intandrandom_big_int, I need to compute lcms, in this case optimized by knowing that the first factor is always small:Finally, Pollard’s p-1:
let pollard_pm1 = let open Big_int in let rec go b k n = let a = add_int_big_int 2 (random_big_int (add_int_big_int (-2) n)) in let g = gcd_big_int a n in if gt_big_int g unit_big_int then g else let d = gcd_big_int (pred_big_int (modexp_big_int a k n)) n in if eq_big_int d n then go b k n else if eq_big_int d unit_big_int then let b = succ b in if b > 1_000_000 then failwith "pollard_pm1" else go b (lcm_int_big_int b k) n else d in let b = 7 in let k = List.fold_right lcm_int_big_int (range 2 b) (List.fold_right mult_int_big_int (primes b) unit_big_int) in all_factors (go b k)This method seems to be much, much slower than Pollard’s Rho.
It shouldn’t be much, much slower than Pollard’s rho. The two methods are complementary. The rho method is generally used to find small factors, say from 4 to 12 digits, after trial division has found factors up to 3 digits. The p-1 method is generally used after the rho method has run for a while, in the hope that you get lucky and find a large factor, say 15 to 20 digits or sometimes more.
It’s been a while since I programmed in the ML family of languages, so I’ll ask some questions instead of making some statements.
1) I see only one bound b. If you look at the more recent p-1 exercise that uses the improved standard continuation, you’ll see a much faster version of the algorithm that uses two bounds b1 and b2.
2) In the pollard_pm1 function, the line let k = …, do you recompute the lcm at each b?
3) I don’t understand the List.fold_right in the line after that. You seem to be taking the product of all the primes less than b, but I’m not sure why.