Minimum Spanning Tree: Prim’s Algorithm
April 9, 2010
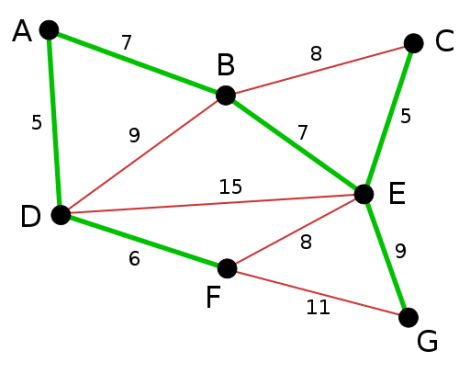 In the previous exercise we studied Kruskal’s algorithm for computing the minimum spanning tree of a weighted graph. Today we study an algorithm developed in 1930 by the Czech mathematician Vojtěch Jarník and rediscovered by Robert Prim in 1957.
In the previous exercise we studied Kruskal’s algorithm for computing the minimum spanning tree of a weighted graph. Today we study an algorithm developed in 1930 by the Czech mathematician Vojtěch Jarník and rediscovered by Robert Prim in 1957.
Kruskal’s algorithm works by creating a singleton tree for each vertex and merging the trees by taking at each step the minimum-weight edge that joins two trees. Prim’s algorithm is the opposite; it starts with a single vertex and repeatedly joins the minimum-weight edge that joins the tree to a non-tree vertex. At each step the tree is a minimum spanning tree of the vertices that have been processed thus far.
Your task is to write a program to find the minimum spanning tree of a graph using Prim’s algorithm. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.

[…] Praxis – Minimum Spanning Tree: Prim’s Algorithm By Remco Niemeijer In today’s Programming Praxis exercise we have to implement an algorithm for finding the minimum spanning tree […]
My Haskell solution (see http://bonsaicode.wordpress.com/2010/04/09/programming-praxis-minimum-spanning-tree-prims-algorithm/ for a version with comments):
import Data.List import qualified Data.List.Key as K prim :: (Eq a, Ord b) => [(a, a, b)] -> [(a, a, b)] prim es = f [(\(v,_,_) -> v) $ head es] [] where f vs t = if null r then t else f (union vs [x,y]) (m:t) where r = filter (\(a,b,_) -> elem a vs /= elem b vs) es m@(x,y,_) = K.minimum (\(_,_,c) -> c) rPython version:
usable_edges is a heap of edges having the first vertex in the MSP and the second vertex might not be in the MSP.
conn is a dictionary mapping verticies to edges. The tuples (c, n1, n2) in the dictionary have the cost first so that the heap operations will return the edges in order of increasing cost.
from collections import defaultdict from heapq import * def prim( nodes, edges ): conn = defaultdict( list ) for n1,n2,c in edges: conn[ n1 ].append( (c, n1, n2) ) conn[ n2 ].append( (c, n2, n1) ) mst = [] used = set( nodes[ 0 ] ) usable_edges = conn[ nodes[0] ][:] heapify( usable_edges ) while usable_edges: cost, n1, n2 = heappop( usable_edges ) if n2 not in used: used.add( n2 ) mst.append( ( n1, n2, cost ) ) for e in conn[ n2 ]: if e[ 2 ] not in used: heappush( usable_edges, e ) return mst #test nodes = list("ABCDEFG") edges = [ ("A", "B", 7), ("A", "D", 5), ("B", "C", 8), ("B", "D", 9), ("B", "E", 7), ("C", "E", 5), ("D", "E", 15), ("D", "F", 6), ("E", "F", 8), ("E", "G", 9), ("F", "G", 11)] print "prim:", prim( nodes, edges ) #output #prim: [('A', 'D', 5), ('D', 'F', 6), ('A', 'B', 7), ('B', 'E', 7), ('E', 'C', 5), ('E', 'G', 9)]this program is not working properly
A good working code for Prim’s Algorithm in C++
http://in.docsity.com/en-docs/Prim_Algorithm_-_C_plus_plus_Code
The code works perfectly fr the example. But line#11 may cause problem if the first node name has two or more characters. “used = set( [nodes[0]] )” to be safe?
Ye… This isn’t working perfectly.
i think:
used = set( nodes[ 0 ] )
must be:
used = set( [nodes[ 0 ]] )
or:
used = {nodes[ 0 ]}
(as lasso said ;-) ; replacement also then works for other nodes)