RIP Leibniz
November 18, 2016
Gottfried Wilhelm Leibnez was a German mathematician and philosopher, and a developer, independently of Isaac Newton, of calculus; it was he who invented the d/dx notation used in writing integrals. He died three hundred years ago, on November 14, 1716, so today (a few days late, sorry) we have an exercise about calculus:
Write a program that computes the average number of comparisons required to determine if a random sequence is sorted. For instance, in the sequence 1 2 3 5 4 6, the first inversion appears between 5 and 4, so it takes four comparisons (1<2, 2<3, 3<5, 5<4) to determine that the sequence is not sorted.
Your task is to write a program as described above. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.

In python:
# outputs: 1.717841
Parameter list_size seems less relevant for increasing value, as the chance that the entire list would be sorted approaches 0.
Instead, sampling the number of random tests to determine that the characters in a given text (a command-line argument to the script) are not in order. Also in Python.
from itertools import count from random import randrange from statistics import mean, median import sys prog, text = sys.argv assert not list(text) == sorted(text) def sample(): '''How many random tests of adjacent characters it took to determine that the characters in text are not in order.''' for k in count(start = 1): p = randrange(1, len(text)) if text[p - 1] > text[p]: return k data = [ sample() for k in range(1000) ] rank = sorted(data) print('number of random test pairs to determine', repr(text), 'is out of order:') print('actual 1000 samples:', *data[:24], end = ' ...\n') print('sorted 1000 samples:', *rank[:10], end = ' ... '); print(*rank[-10:]) print('mean tests:', mean(data)) print('median tests:', median(data)) print('quartile tests:', rank[250], rank[500], rank[750]) # close enough # number of random test pairs to determine 'abracadabra' is out of order: # actual 1000 samples: 3 1 4 1 8 1 11 4 1 2 2 3 2 1 3 1 2 1 1 7 3 5 12 1 ... # sorted 1000 samples: 1 1 1 1 1 1 1 1 1 1 ... 10 10 10 10 10 10 11 12 12 13 # mean tests: 2.487 # median tests: 2.0 # quartile tests: 1 2 3Randomness in Haskell is not my forte, so I went with a brute force approach; given a list,
calculate the number of comparisons needed for each permutation of that list and take the
average. I used the foldl package, but everything else is in the standard library.
module Main where import qualified Control.Foldl as L import Data.List (permutations) mean = (/) <$> L.Fold (+) 0 fromIntegral <*> L.genericLength numComp [] = 0 numComp [x] = 0 numComp (x:y:zs) | x > y = 1 | otherwise = 1 + numComp (y : zs) brute = L.fold mean . map numComp . permutations main = print $ brute [1 .. 10]We can save ourselves a lot of work by only randomizing the array as far as the first inversion, here we use a standard Fisher-Yates shuffle, but stop exchanges once an inversion is discovered. As Rutger observes, we don’t need a very large array for the probability of getting to the end to become negligible (we print out the distribution here as well as the result). Javascript since I’m trying to get into ES6 at the moment:
function trial(a) { const N = a.length for (let i = 0; i < N; i++) { var k = i + Math.floor(Math.random()*(N-i)) var t = a[k] if (i > 0 && t < a[i-1]) return i; // Inversion a[k] = a[i]; a[i] = t; } return N; } function f(N,count) { const a = Array(N).fill(0).map((a,i) => i) let total = 0, counts = [0] for (let n = 0; n < count; n++) { let k = trial(a) counts[k] = (counts[k]|0)+1 total += k } console.log(total/count, counts) } f(20,10000) f(20,100000) f(20,1000000) f(20,10000000)And in a similar vein, like Graham’s solution (shame not to get monads in there, as Leibniz seems to have invented the term), we can generate permutations and count the number of comparisons – but we only need to find all possible initial segments of permutations with a single inversion at the end of the segment, then if the initial segment has length n and there are N elements altogether, this actually counts as (N-n)! different permutations – for N = 10, we actually look at 4097 initial segments, rather than 10! = 3628800 full permutations.
function test(N) { const fact = (n) => n == 0 ? 1 : n*fact(n-1) const a = Array(N).fill(0).map((a,i) => i) const counts = Array(N).fill(0) function aux(i) { for (let k = i; k < N; k++) { [a[i],a[k]] = [a[k],a[i]] // Swap if (a[i-1] > a[i]) { console.log(a.slice(0,i+1)) counts[i]++ } else { aux(i+1); } [a[i],a[k]] = [a[k],a[i]] // Swap back } } aux(0) let total = 0 for (let i = 1; i < N; i++) { total += i*counts[i]*fact(N-i-1) } console.log(total/fact(N),counts) }For N = 4 we get:
and for N = 19, we get a final result of 1.7182818284590453, about as good as it gets with 64-bit floats.
In Python. Sequences longer than 10 are not really useful, as the inversion only very rarely happens with an index higher than 9.
from math import e, factorial from itertools import permutations def is_sorted(seq): return next((i for i, (a, b) in enumerate(pairwise(seq), 1) if a > b), len(seq)) def test(lenseq): return (sum(is_sorted(p) for p in permutations(range(lenseq))) / factorial(lenseq)) for L in range(4, 12): print("{:2d} {:12.9f}".format(L, test(L))) print("e-1{:12.9f}".format(e-1)) """ 4 1.708333333 5 1.716666667 6 1.718055556 7 1.718253968 8 1.718278770 9 1.718281526 10 1.718281801 11 1.718281826 e-1 1.718281828 """@Paul: nice, my figures ought to agree with your figures, but they don’t – the problem is in my code, I don’t take account of the single sorted permutation, which we can say requires N comparisons (even if it really only needs N-1). We now converge a bit faster, but still need to go up to N=17 to get full precision:
function test(N) { const fact = (n) => n == 0 ? 1 : n*fact(n-1) const a = Array(N).fill(0).map((a,i) => i) const counts = Array(N).fill(0) function aux(i) { for (let k = i; k < N; k++) { [a[i],a[k]] = [a[k],a[i]] // Swap if (a[i-1] > a[i]) { counts[i]++ } else { aux(i+1); } [a[i],a[k]] = [a[k],a[i]] // Swap back } } aux(0) let total = 0 for (let i = 1; i < N; i++) { total += i*counts[i]*fact(N-i-1) } total += N // The sorted permutation console.log(N,total/fact(N)) } for (var i = 0; i < 20; i++) test(i) console.log("e ",Math.exp(1))@matthew. I agree. I worked out too that you would need to go to 17 for full precision. My Python code is too slow to go to 17 though.
@Paul: We can’t “skip” permutations with the Python itertools function, but we can with a C++-style next_permutation function – having found an initial segment ending in an inversion, we can change the permutation to be the lexically last permutation with that prefix – since we start with the lexically first, we can just reverse the rest of the permutation, as in this C++:
#include <stdio.h> #include <math.h> #include <algorithm> double fact(int n) { return (n <= 1) ? 1 : n * fact(n-1); } double test(int N) { char s[N]; int counts[N]; for (int i = 0; i < N; i++) { s[i] = 'a' + i; counts[i] = 0; } do { for (int i = 1; i < N; i++) { if (s[i-1] > s[i]) { // Inversion found //printf("%d: %.*s\n",i,i+1,s); counts[i]++; // Skip to last permutation with this prefix std::reverse(s+i+1,s+N); break; } } } while(std::next_permutation(s,s+N)); double res = 0; for (int i = 1; i < N; i++) { //printf("%d %d %.16g\n", i, counts[i],fact(N-i-1)); res += i*counts[i]*fact(N-i-1); } res += N; // For the in-order permutation return res/fact(N); } int main() { for (int i = 0; i <= 20; i++) { printf("%d: %.16g\n",i,test(i)); } printf("e: %.16g\n",exp(1)); }Even for N=20 we only need to look at 9437186 permutations rather than the full 20! = 2432902008176640000, which would take a while:
Here is my take on this challenge in Julia. No assumptions are made about the length of the random sequence, or the number of runs for the simulation. However, it appears that the average number of comparison is independent of the sequence length and probably converges to a particular value.
function leibniz(X::Array{Int64, 1})
# X is a random sequence of integers that we wish to determine if it is sorted
c = 0
for i = 2:length(X)
c += 1
if X[i-1] > X[i]
break
end
end
return c
end
function main(n::Int64, N::Int64 = 1000)
# wrapper for leibniz(), for a simulation of N runs
z = 0
for i = 1:N
x = rand(Int64, n)
z += leibniz(x)
end
return z / N
end
julia>main(10, 1000) # try out 1000 random sequences, each one of length 10, and find the average number of comparisons required
1.718
BTW, Happy Thanksgiving everyone!
@Zack, that’s interesting. Others here are interpreting “random sequence” as a random permutation, like a shuffle of a range. You just generate integers and seem to get the same results. But you generate from a large set. The important thing seems to be the low probability of ties. So low that it doesn’t really matter. This is rather under-stated in the problem, as far as I can see, but apparently intended, so that the result is related to a specific constant.
Here, I modified your code to take float arrays (really any numeric arrays), and to use (in-place) shuffles of a given randomly-generated array:
function leibniz{T<:Number}(X::Array{T}) # X is a random sequence of numbers that we wish to determine if it is sorted c = 0 for i = 2:length(X) c += 1 X[i-1] <= X[i] || break end return c end function main!{T<:Number}(x::Array{T}, N = 1000) z = 0 for i = 1:N shuffle!(x) z += leibniz(x) end return z / N endAnd I compute the results with samples from different distributions, first with practically no ties, then rounded to integers so that there will be many ties, and now the ties are seen to affect the result:
println("1000-average position of the first inversion in a shuffle ...") println() println("... of 100 numbers floating as they are (twice):") println("Uniform [0 .. 1)\t$(main!(rand(100)))\t$(main!(rand(100)))") println("Exponential(1)\t\t$(main!(randexp(100)))\t$(main!(randexp(100)))") println("Normal(0, 1)\t\t$(main!(randn(100)))\t$(main!(randn(100)))") println() println("... of 100 numbers floating as rounded to integer (twice):") println("Uniform [0 .. 1)\t$(main!(map(round, rand(100))))\t$(main!(map(round, rand(100))))") println("Exponential(1)\t\t$(main!(map(round, randexp(100))))\t$(main!(map(round, randexp(100))))") println("Normal(0, 1)\t\t$(main!(map(round, randn(100))))\t$(main!(map(round, randn(100))))") # 1000-average position of the first inversion in a shuffle ... # # ... of 100 numbers floating as they are (twice): # Uniform [0 .. 1) 1.736 1.723 # Exponential(1) 1.75 1.719 # Normal(0, 1) 1.737 1.703 # # ... of 100 numbers floating as rounded to integer (twice): # Uniform [0 .. 1) 2.962 2.934 # Exponential(1) 2.283 2.344 # Normal(0, 1) 2.286 2.316 # # Unusual for rounded exponentials and normals to be this close to # each other. Bad luck on this run. Just an impression, though.@matthew: nice and fast trick. I build a version in Python, that works a lot faster, than my earlier version. t took me a while to get it right.
@Paul: thanks, I tried converting my solution above into Python – I seemed to have missed a check that i > 0, does no harm in the Javascript, but not good in Python where we end up indexing from the end of the array. We can also get more significant figures by using big integers:
from math import factorial def test(N): a = range(N); counts = [0]*N def aux(i): for k in range(i,N): if i > 0 and a[i-1] > a[k]: counts[i] += 1 else: a[i],a[k] = a[k],a[i] # Swap aux(i+1); a[i],a[k] = a[k],a[i] # Swap back aux(0) total = 0 for i in range(1,N): assert(counts[i]*factorial(N-i-1) == factorial(N)*i/factorial(i+1)) total += i*counts[i]*factorial(N-i-1) total += N print(N,total*pow(10,20)/factorial(N)) for i in range(23): test(i)Looking at the maths: there are n! sequences of n items and there are n!/(n-k)! different initial sequences of k items of which n!/(k!(n-k)!) are ordered (ie. n choose k); each initial sequence appears (n-k)! times in the list of all sequences. A sequence with k ordered items initially needs at least k comparisons, if the first k items are not ordered, then at most k-1 comparisons are needed. Putting all this together: the proportion of all sequences that require k or more comparisons is (n!/(k!(n-k)!))/(n!/(n-k)!, which is just 1/k! and the proportion that require exactly k comparisons is then just 1/k! – 1/(k+1)! = k/(k+1)! and expected number of comparisons is sum of k²/(k+1)! Still not quite sure why the sum is e-1, but working on it.
@matthew. PP metions the blog of Colin Stedman. If you take formula 5 (where btw all the n’s should be i’s), you can easily calculate the result. A good trick is to write i^2 as i*(i+1) – (i+1) + 1. This leads to the sum of 3 terms: t1-t2+t3 = e – (e-1) + (e-2) = e-1 if you let go n to infinity.
@Paul: Aha, that identity for i^2 is just what I want, thanks. I’d looked at Collin’s page, but not entirely followed the reasoning (hence my reworking up above).
def comparisons_until_unsorted(list, steps=0) head, *tail = list if tail.empty? steps elsif head > tail.first steps + 1 else comparisons_until_unsorted(tail, steps + 1) end end def average_comparisons_to_sort(length, passes=1000000) list = (1..length).to_a passes. times. map { comparisons_until_unsorted(list.shuffle) }. reduce(0.0, &:+) / passes end (4..20).each do |n| puts "#{n}: #{average_comparisons_to_sort(n)}" endOutputs:
4: 1.666927
5: 1.706343
6: 1.714978
7: 1.719484
8: 1.717933
9: 1.715861
10: 1.717179
11: 1.718295
12: 1.717068
13: 1.718003
14: 1.718197
15: 1.718366
16: 1.718356
17: 1.717484
18: 1.719986
19: 1.718612
20: 1.718551
Forgot to mention that the above solution is in Ruby.
(English isn’t my first language, so please excuse any mistakes. I have used Unicode character U+222B for the integrals, I hope the comment system will not garble it.)
A mathematical solution that actually uses integrals and that is (more or less) rigorous (whereas Collin Stedman, in his nice article, assumes without proof that a certain sequence matches a certain formula):
Let S be the length of the nondecreasing initial subsequence of a sequence of random numbers taken from the interval [0, 1]. Thus, if the sequence is
0.2 0.1 0.3 …
then S is 1, and if the sequence is
0.2 0.25 0.7 0.5 …
then S is 3. S equals the number of comparisons that it takes to determine that the sequence is not sorted. The problem is to compute E(S), the expected value of S.
First, condition E(S) on the value of the first element of the sequence. Imagine that the interval [0, 1] is divided into a very large number of very small subintervals of length dx. Since the value of each element is assumed to be uniformly distributed on [0, 1], the probability that the first element will lie in some subinterval [x, x + dx] is just dx. Hence,
E(S) = ∫(x from 0 to 1) E(S | first element is x) Prob(first element lies in [x, x + dx])
= ∫(x from 0 to 1) E(S | first element is x) dx. [*]
Let f(x) be a shorthand for E(S | first element is x). The reason I introduce this function is that, using recursion as an inspiration, a relatively simple equation can be written down for it. The key idea is to look at the next (that is, second) element of the sequence and condition f(x) on its value as compared to the value of the first element, that is, x. Thus,
f(x) = ∫(y from 0 to 1) f(x | second element is y) Prob(second element lies in [y, y + dy])
= ∫(y from 0 to 1) f(x | second element is y) dy.
Now there are two possibilities. Either x <= y, and then f(x | second element is y) equals one plus the expected value of S for the _rest_ of the sequence, given that _its_ first value is y. But this last expected value is, by definition, f(y). So this possibility contributes to f(x) an amount of
∫(y from x to 1) (1 + f(y)) dy
= 1 – x + ∫(y from x to 1) f(y) dy.
(Note the integration limits: x y, then the expected value of S is, of course, 1, so this contributes to f(x) an amount of
∫(y from 0 to x) 1 dy
= x.
(Note again the integration limits.) Hence, we have
f(x) = 1 – x + ∫(y from x to 1) f(y) dy + x
= 1 + ∫(y from x to 1) f(y) dy.
You could say that this is the analytical form of the function
(let loop ((xs xs) (count 1))
(cond ((null? (cdr xs)) count)
((lt? (car xs) (cadr xs))
(loop (cdr xs) (+ count 1)))
(else count))))
from the webmaster’s suggested solution, and especially of the line
(loop (cdr xs) (+ count 1))).
The equation is a so-called linear Volterra integral equation. Now I don’t know much about integral equations, but I do know one solution technique and it happens to work in this case: take the Laplace transform of both sides, solve for the transform of the unknown function, and then take the inverse Laplace transform. To do this here, it is necessary first to rewrite the integral so that the lower limit of integration becomes zero:
f(x) = 1 + ∫(y from 0 to 1) f(y) dy – ∫(y from 0 to x) f(y) dy.
That second term seems pesky, but if you look back at equation [*], it turns that it equals E(S) itself. So the integral equation becomes
f(x) = 1 + E(S) – ∫(y from 0 to x) f(y) dy.
Now take the Laplace transform and call the transform of f(x), F(p). If, in the transform of the last term, you change the order of integration, it simplifies nicely to F(p) / p. So we get
F(p) = (1 + E(S)) / p + F(p) / p.
Solving for F(p) gives
F(p) = (1 + E(S)) / (p + 1).
Taking the inverse transform gives
f(y) = (1 + E(S)) exp(-y).
(Aha, there’s our friend exp!) Now, returning once more to equation [*], we get
E(S) = ∫(x from 0 to 1) f(x) dx
= ∫(x from 0 to 1) (1 + E(S)) exp(-x) dx
= (1 + E(S)) (1 – 1/e).
Finally, we solve for E(S) and get
E(S) = e – 1.
In my previous post, the less-than-or-equal-sign was apparently interpreted as a tag and this caused a part of the text to be removed. Second attempt:
(English isn’t my first language, so please excuse any mistakes. I have used Unicode character U+222B for the integrals, I hope the comment system will not garble it.)
A mathematical solution that actually uses integrals and that is (more or less) rigorous (whereas Collin Stedman, in his nice article, assumes without proof that a certain sequence matches a certain formula):
Let S be the length of the nondecreasing initial subsequence of a sequence of random numbers taken from the interval [0, 1]. Thus, if the sequence is
0.2 0.1 0.3 …
then S is 1, and if the sequence is
0.2 0.25 0.7 0.5 …
then S is 3. S equals the number of comparisons that it takes to determine that the sequence is not sorted. The problem is to compute E(S), the expected value of S.
First, condition E(S) on the value of the first element of the sequence. Imagine that the interval [0, 1] is divided into a very large number of very small subintervals of length dx. Since the value of each element is assumed to be uniformly distributed on [0, 1], the probability that the first element will lie in some subinterval [x, x + dx] is just dx. Hence,
E(S) = ∫(x from 0 to 1) E(S | first element is x) Prob(first element lies in [x, x + dx])
= ∫(x from 0 to 1) E(S | first element is x) dx. [*]
Let f(x) be a shorthand for E(S | first element is x). The reason I introduce this function is that, using recursion as an inspiration, a relatively simple equation can be written down for it. The key idea is to look at the next (that is, second) element of the sequence and condition f(x) on its value as compared to the value of the first element, that is, x. Thus,
f(x) = ∫(y from 0 to 1) f(x | second element is y) Prob(second element lies in [y, y + dy])
= ∫(y from 0 to 1) f(x | second element is y) dy.
Now there are two possibilities. Either x is less than or equal to y, and then f(x | second element is y) equals one plus the expected value of S for the _rest_ of the sequence, given that _its_ first value is y. But this last expected value is, by definition, f(y). So this possibility contributes to f(x) an amount of
∫(y from x to 1) (1 + f(y)) dy
= 1 – x + ∫(y from x to 1) f(y) dy.
(Note the integration limits: ‘x less than or equal to y’ means that y runs from x to the maximum value of 1.) If, on the other hand, x > y, then the expected value of S is, of course, 1, so this contributes to f(x) an amount of
∫(y from 0 to x) 1 dy
= x.
(Note again the integration limits.) Hence, we have
f(x) = 1 – x + ∫(y from x to 1) f(y) dy + x
= 1 + ∫(y from x to 1) f(y) dy.
You could say that this is the analytical form of the function
(let loop ((xs xs) (count 1))
(cond ((null? (cdr xs)) count)
((lt? (car xs) (cadr xs))
(loop (cdr xs) (+ count 1)))
(else count))))
from the webmaster’s suggested solution, and especially of the line
(loop (cdr xs) (+ count 1))).
The equation is a so-called linear Volterra integral equation. Now I don’t know much about integral equations, but I do know one solution technique and it happens to work in this case: take the Laplace transform of both sides, solve for the transform of the unknown function, and then take the inverse Laplace transform. To do this here, it is necessary first to rewrite the integral so that the lower limit of integration becomes zero:
f(x) = 1 + ∫(y from 0 to 1) f(y) dy – ∫(y from 0 to x) f(y) dy.
That second term seems pesky, but if you look back at equation [*], it turns that it equals E(S) itself. So the integral equation becomes
f(x) = 1 + E(S) – ∫(y from 0 to x) f(y) dy.
Now take the Laplace transform and call the transform of f(x), F(p). If, in the transform of the last term, you change the order of integration, it simplifies nicely to F(p) / p. So we get
F(p) = (1 + E(S)) / p + F(p) / p.
Solving for F(p) gives
F(p) = (1 + E(S)) / (p + 1).
Taking the inverse transform gives
f(y) = (1 + E(S)) exp(-y).
(Aha, there’s our friend exp!) Now, returning once more to equation [*], we get
E(S) = ∫(x from 0 to 1) f(x) dx
= ∫(x from 0 to 1) (1 + E(S)) exp(-x) dx
= (1 + E(S)) (1 – 1/e).
Finally, we solve for E(S) and get
E(S) = e – 1.
@Johan: nice analysis. My calculus is very rusty (and wasn’t that great to start with), but can we do some trick like differentiating both sides of:
(if my embedded latex comes out).
https://en.support.wordpress.com/latex/ by the way.
@matthew: thank you, and you are perfectly right about the differentiation trick. It leads to a simple differential equation for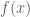 and from there to the solution
and from there to the solution  , using the initial value
, using the initial value  that follows from the integral equation. It also obviates the need to rewrite the integral equation and to recognize that ‘pesky term’ as $E(S)$. I have a habit of making such calculations more complex than necessary, although in this case it might have been my fondness for the Laplace transform that made me overlook the simpler solution. :-)
that follows from the integral equation. It also obviates the need to rewrite the integral equation and to recognize that ‘pesky term’ as $E(S)$. I have a habit of making such calculations more complex than necessary, although in this case it might have been my fondness for the Laplace transform that made me overlook the simpler solution. :-)
@Johan: Well, going the more complicated route is often more educational.